El día de hoy empezaremos a trabajar sobre el reto de nforiver & FP20 Analytics Challenge está lanzando el desafío «HR DATA ANALYSIS», el cual si aun no estas informado te comparto el link del Grupo https://www.linkedin.com/groups/12751070/ y el link del reto https://fp20analytics.com/challenge para que te unas y empecemos a trabajar sobre el.
Antes de abrir el Power BI que nos comparten en el reto, te aconsejo abrir el CSV con el dato , entender las columnas, las preguntas de negocio he ir evaluando como responderás las preguntas planteadas, y trata desde tu punto de vista crear un modelo de datos que responda de manera mas optima las preguntas de negocio, la idea de estos restos es plantearnos preguntas como analista de datos y tener criterios de decisión y análisis para responder, esto es lo que estaré compartiendo.
Partamos del punto de vista que, si o si debemos entender que debemos crear un modelo de datos dimensional, tabla de hechos y tabla de dimensiones, debemos entender cómo manejar este proceso, y con este CSV podremos entender como hacerlo.
En este caso debemos entender el proceso , lo primero siempre es revisar que data tenemos y que data podemos utilizar , es decir que tipos de datos podemos manejar, columnas vacías, duplicados y entender los datos.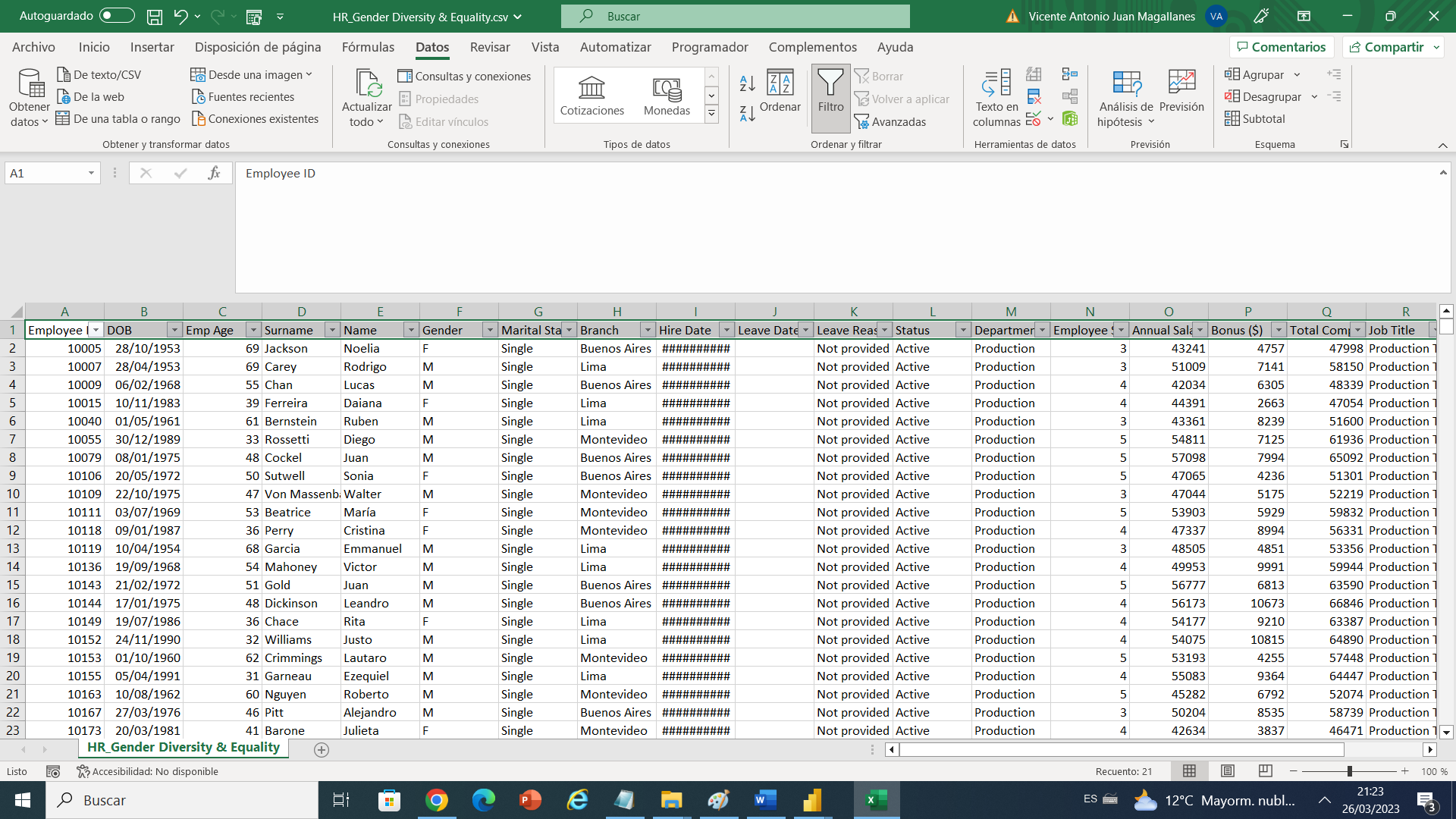
Haciendo este análisis encontramos que tenemos datos duplicados bueno no absolutamente duplicados pero, tenemos dos opciones o están duplicados o tuvieron un ajuste salarial en el mismo año de contratación, descartamos asenso por siguen manteniendo el cargo, los ID duplicados son.
Id duplicados
| 10021 |
| 10131 |
| 10021 |
| 10131 |
| 10284 |
| 10284 |
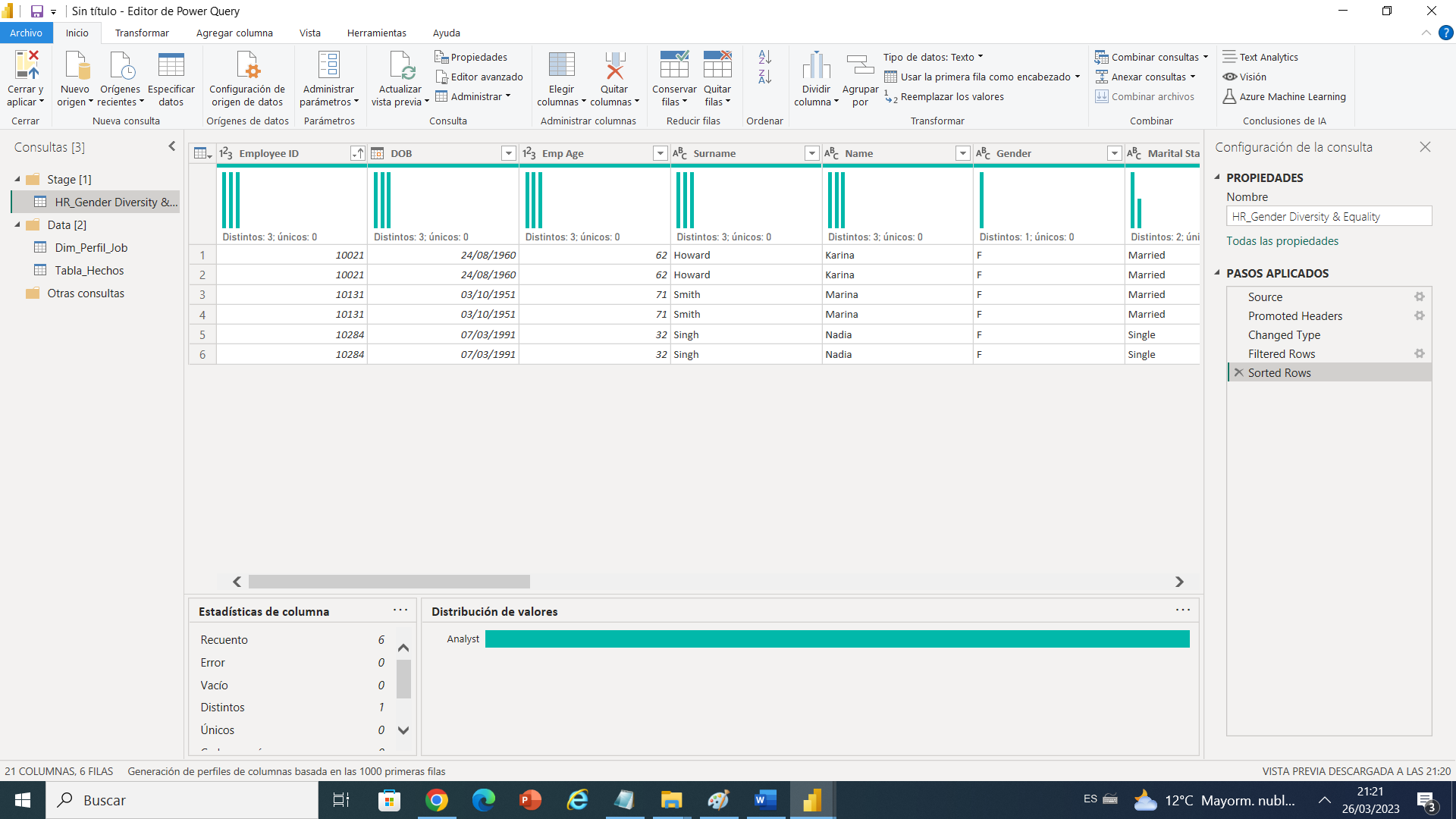
Como vemos solo cambio la compensación el bono o el salario anual, si fuera el caso de un cliente real podríamos preguntar si desea conservarlo o no, pero esto afectaría las diferentes medidas que ya se nos plantearon como preguntas de negocio, así que en mi caso eliminare duplicados para quedarme con uno de estos.
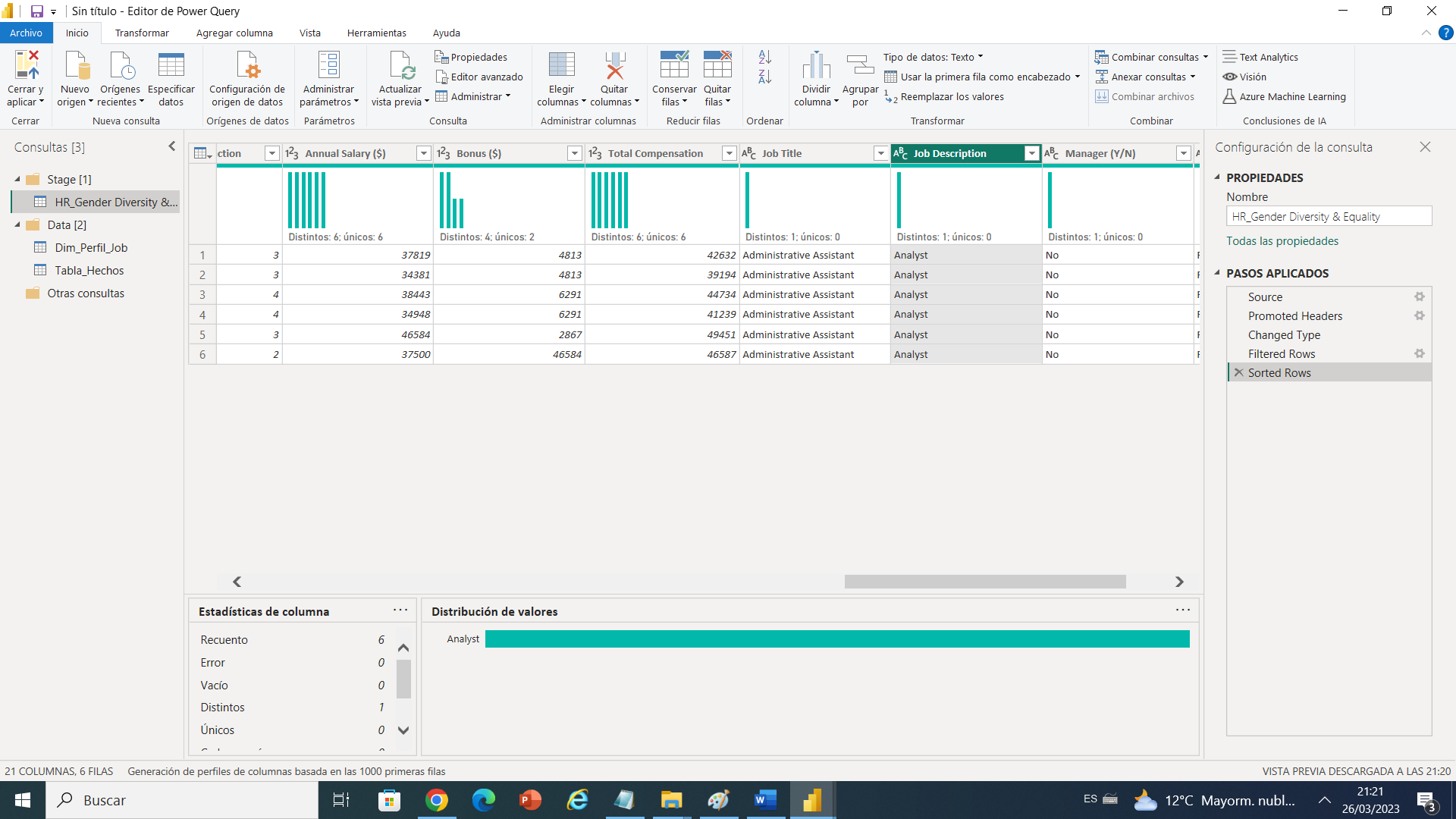
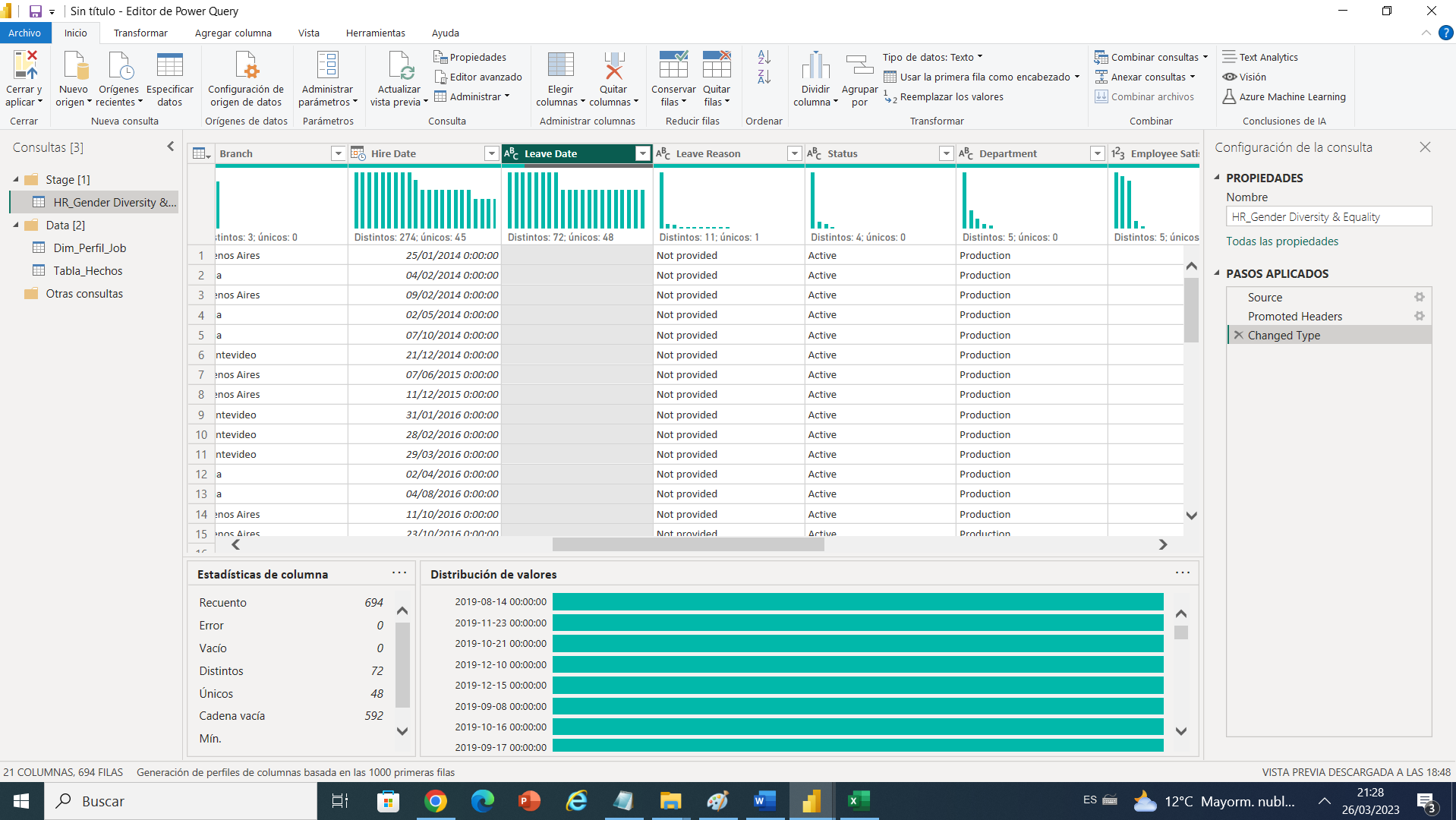
Ahora podemos observar que tenemos la columna Leave Date con filas en blanco , se entiende por qué son trabajadores que aun siguen activos en la empresa , esta columna fecha no le deseo dejar en blanco, así que si podemos dejarla de esta manera y claro esta cambiarle el tipo de dato a solo fecha dado que no deseamos que tener hora .
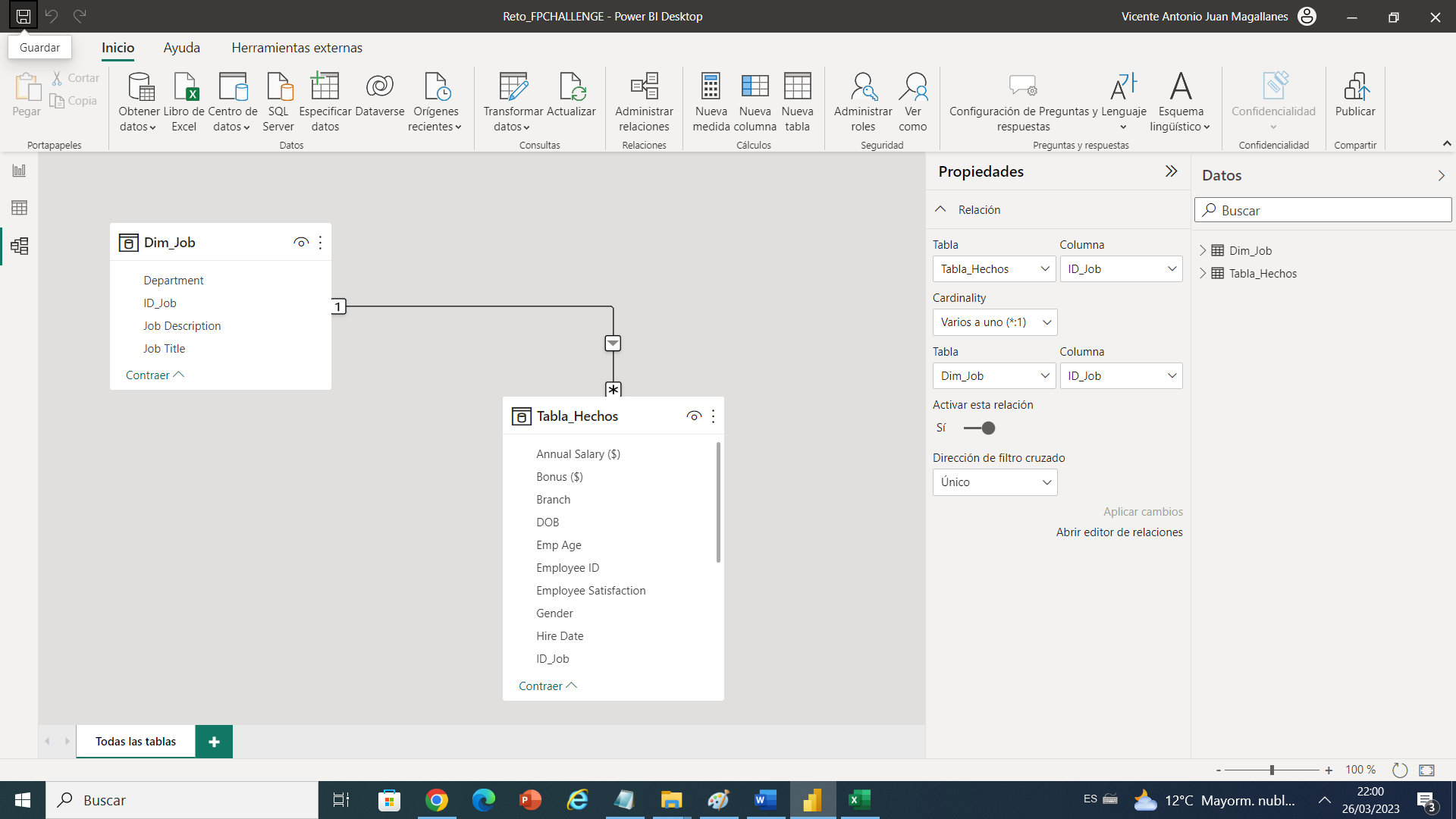
Pasaremos a crear nuestra primera dimensión la cual es Dim_Job, lo que me planteo para este dimensión son dos casos en uno estaba analizando, dado que podría crear una dimensión para departamento y otra para Job Title y Job Description, por que podríamos tener el caso que el trabajador de la compañía lo modificaron de área o fue ascendido entonces será conveniente dejarlas aparte , pero repito ya tenemos las preguntas de negocio hechas y no hace falta esto así que podemos tener las tres columnas en una sola Dimensión.
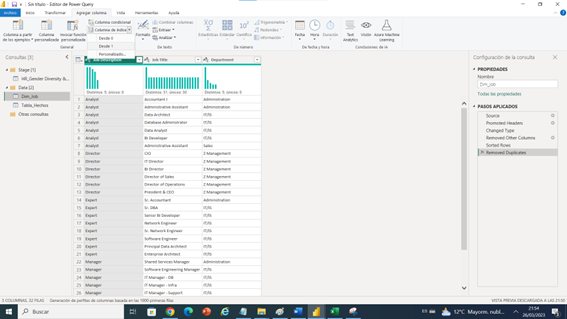
Realizaremos la creación de dimensiones en power query.
Ahora lo primero será evaluar que columnas queremos para esta dimensión las cuales serán departamento, Job Title y Job Description.
Ahora teniendo la dimensión extraída de la tabla origen debemos eliminar Duplicado , que columna es la cual me identifica que debo eliminar en este caso debes eliminar las columnas con la mayor cantidad de datos diferentes únicos, en este caso departamento son 5 , lo mismo para Job Title y la que se debe tener en cuenta es Job Description el cual es el que cumple este requisito con 31, con lo cual al eliminar dejaremos las combinaciones únicas para lograr la relación de 1 a muchos hacia la tabla de hechos.
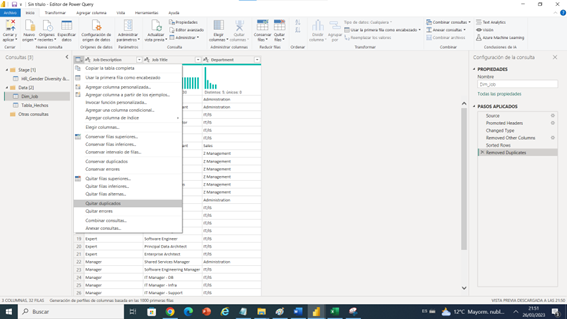
Para probar si esto funciona debemos entender que probamos cruzar la tabla que creamos de dimensión con la tabla de hechos y todos deben hacer macth para garantizar que no dejaremos ninguno por fuera, y utilizando las tres columnas en orden primero Job Description, segunda columna que cruzamos Job Title por ultimo departamento, teniendo este valorado.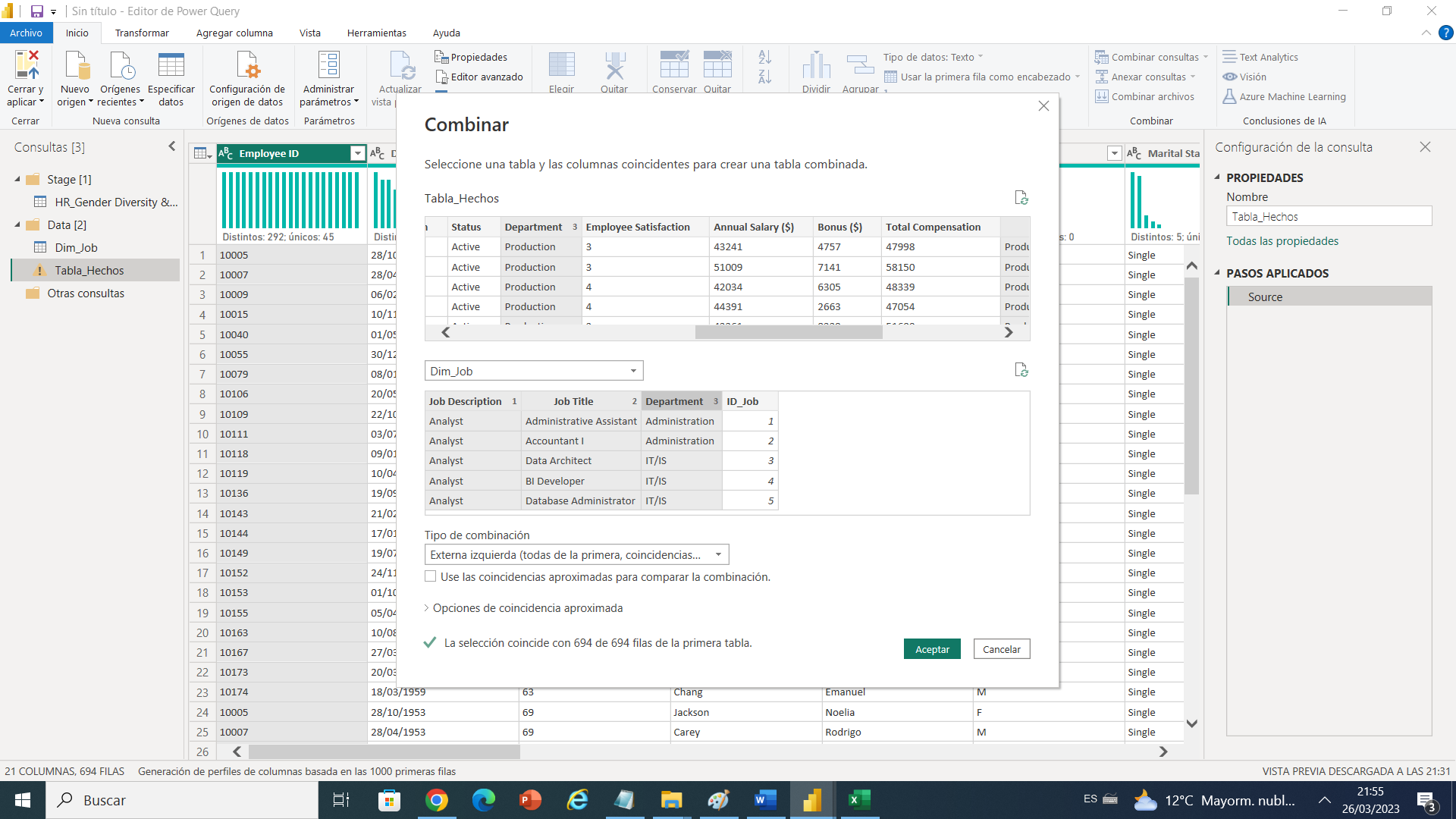
Pasamos a crear una columna auto incrementable de tipo subrogada .
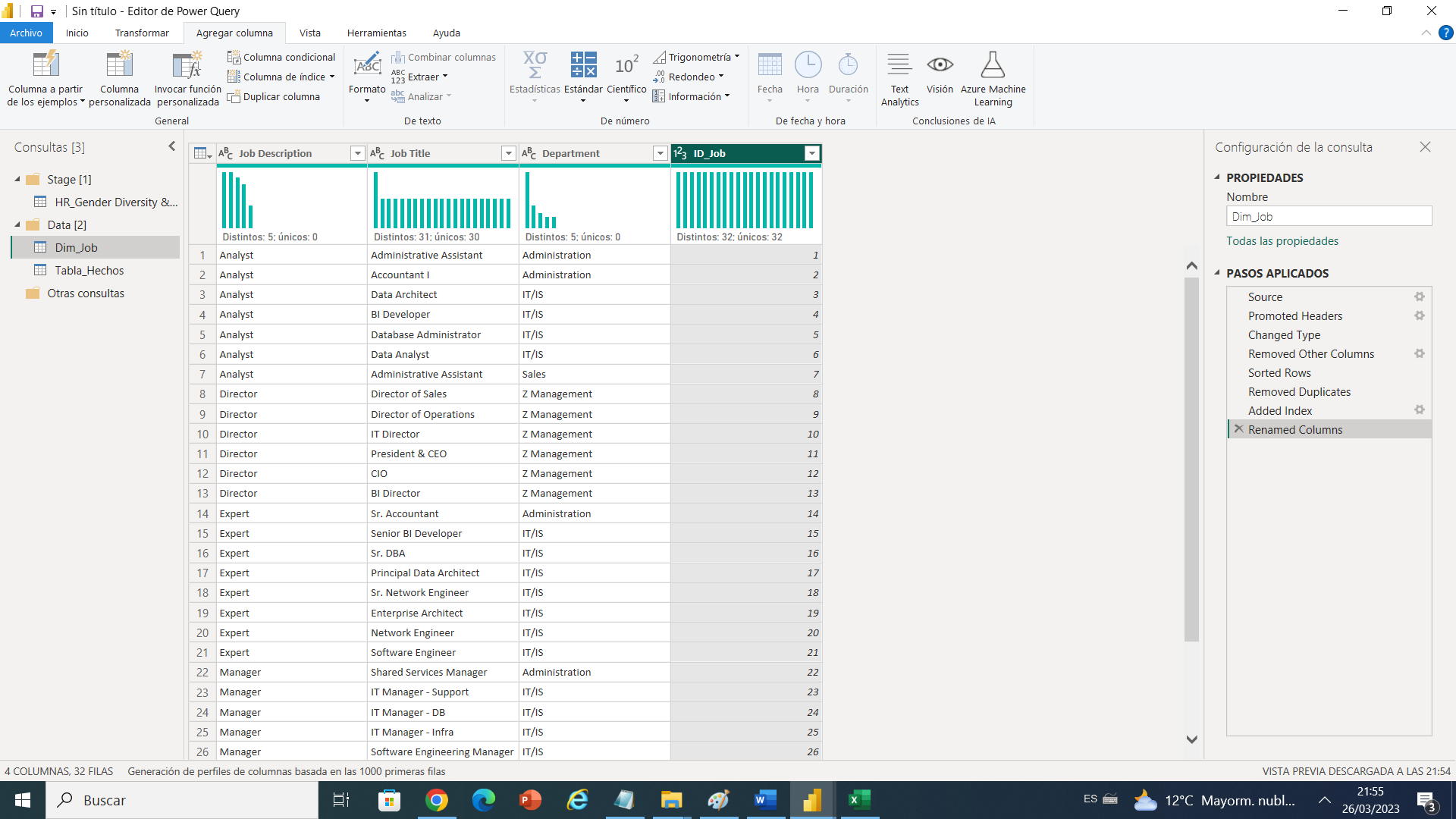
Luego creamos la consulta de combinar para hacer el cruce con los campos anteriores y llevar la clave subrogada de nuestra dimensión hacia la tabla de hechos.
Pudiendo eliminar las tres columnas y dejando el ID_Job.
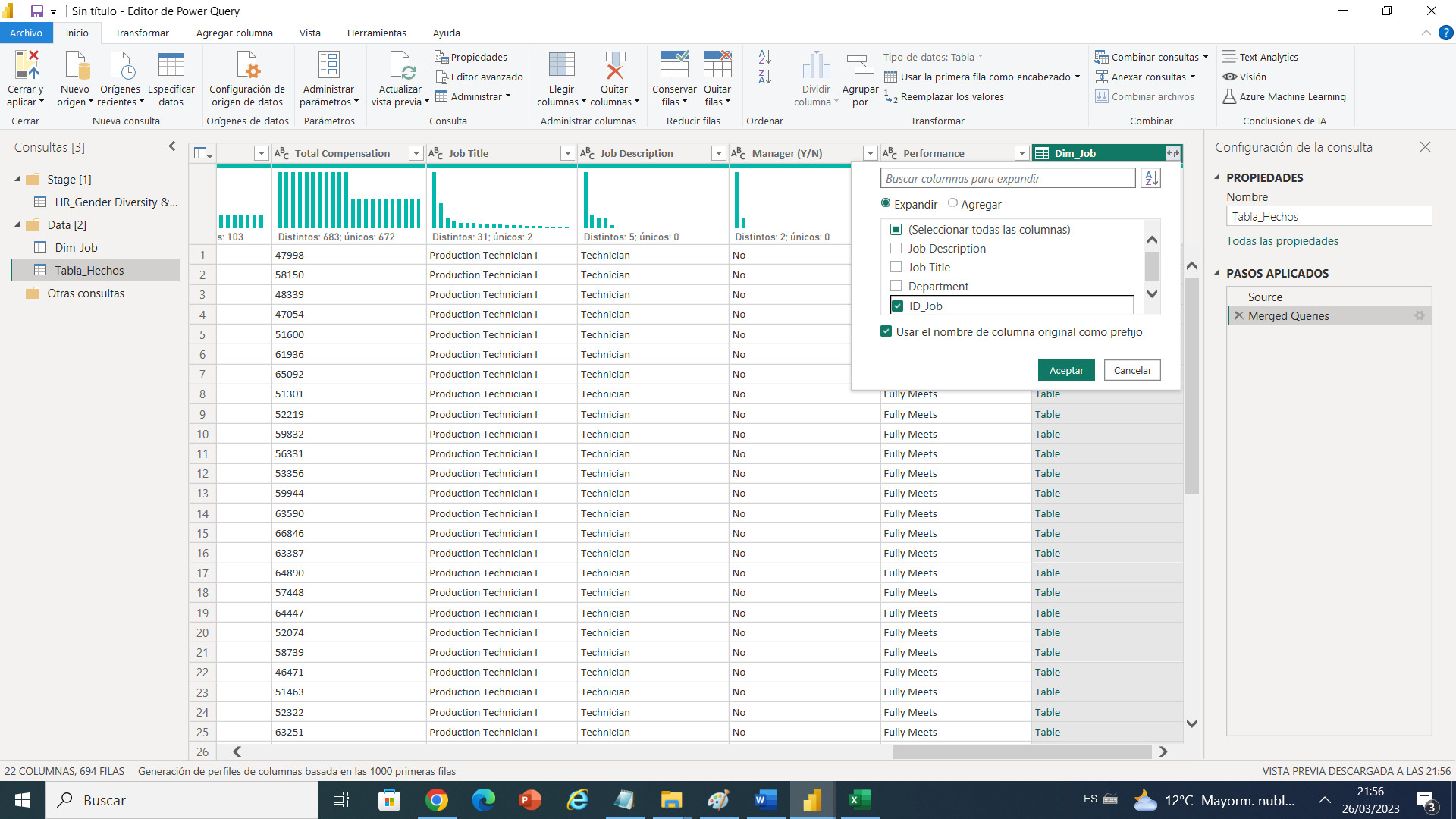
Como vemos hemos identificado duplicados, creamos criterios para la primera dimensión, y así vamos optimizando nuestro modelo de datos para este fantástico reto en el cual podemos colocar en práctica nuestros conocimientos del área de BI
Te invito a participar en el reto, y a estar pendiente de las publicaciones ya que día a día estaré subiendo lo que vaya realizando para cada reto.
Vicente Antonio Juan Magallanes
Business Intelligence Technical.

Perfil linkedin.