
¡Bienvenidos, muy buenos días tardes o noches , según donde me leas !
En la era de la información, los datos son el activo más valioso para empresas y organizaciones de todo tipo. Sin embargo, la simple acumulación de datos no garantiza su utilidad; es esencial someterlos a un riguroso proceso de evaluación y limpieza para extraer información significativa y confiable. En este artículo, exploraremos un enfoque personal para llevar a cabo la evaluación y limpieza de datos, utilizando herramientas como Excel, Power Query y Python.
El primer paso en nuestro proceso es migrar los datos a Excel utilizando Power Query. Una vez en Excel, cargamos los datos en una tabla para facilitar su manipulación. Desde allí, nos adentramos en la crucial tarea de limpiar los datos, comenzando por abordar los valores faltantes.
El manejo de valores faltantes es fundamental para garantizar la integridad de nuestros análisis. A través de Power Query, identificamos los valores faltantes y evaluamos su impacto en nuestro conjunto de datos. Utilizando criterios cuidadosamente definidos, decidimos si eliminar los registros con valores faltantes o aplicar técnicas de imputación para llenar los vacíos.
Una vez completada la limpieza inicial, nos sumergimos en la estandarización de criterios categóricos, centrándonos en este caso en la normalización de los nombres de empresas. Utilizando Python, creamos un código para calcular la similitud entre los nombres de las empresas y estandarizarlos en base a criterios específicos.
Con los nombres de empresas estandarizados, avanzamos hacia un análisis más profundo de nuestros datos, explorando aspectos como la distribución de precios y la cantidad de empresas distintas en nuestro conjunto de datos. Este análisis nos proporciona una comprensión más completa de la naturaleza y la calidad de nuestros datos, preparándonos para futuros pasos, como la creación de modelos de datos y la generación de insights para la toma de decisiones empresariales.
Pasos personales para una evaluación y limpieza de datos (En este caso usando Excel, power query y Python):
Migrar el CSV, en este caso, hacia Excel con Power Query.
Cargarlo en una tabla.
Primero Power Query solo nos da los valores iniciales para el proceso de validación de datos, es decir, 1000 registros de 34755 registros, es menos del 10%, así que prefiero cargarlo en formato tabla y empezar a realizar mi limpieza.
Existen varias maneras de limpiar datos y organizarlos para cargarlos. En este caso, te explicaré la que usé para nuestro reto de datos.
Primero debemos:
Manejo de valores faltantes: Identificar y decidir cómo tratar los valores faltantes en el conjunto de datos. Puedes optar por eliminar registros con valores faltantes, imputar los valores faltantes utilizando técnicas como el promedio, la mediana o modelos de imputación más avanzados, o mantener los registros con valores faltantes si son pocos y no afectan significativamente el análisis.
Donde puedo identificar qué tipo de datos atípicos tenemos en nuestra Power Query, podemos ver que tenemos datos vacíos (Imagen 1).
Como podemos ver, tenemos múltiples datos vacíos, en los cuales debemos entender:
Identificar los valores faltantes: Este paso ya está completado porque ya sabemos que efectivamente tenemos datos faltantes, sea con Power Query o en formato tabla llevando a un Excel el archivo (Imagen 2).

Evaluar el impacto de los valores faltantes: Determina cuántos valores faltantes hay en tu conjunto de datos y qué impacto tienen en tu análisis. Si solo hay unos pocos valores faltantes o si están distribuidos de manera aleatoria, es posible que puedas ignorarlos. Sin embargo, si hay muchos valores faltantes o si están concentrados en ciertas variables importantes, es necesario abordarlos. Afortunadamente, para nuestro caso, el primer bloque de valores faltantes no está aleatoriamente distribuido; se encuentran en líneas seguidas. Igualmente, es aconsejable realizar una prueba eliminando los datos vacíos y leer el resultado de nuestra sabana de datos. Para hacer esto, nos apoyamos en nuestra herramienta Power Query (Imagen 3).
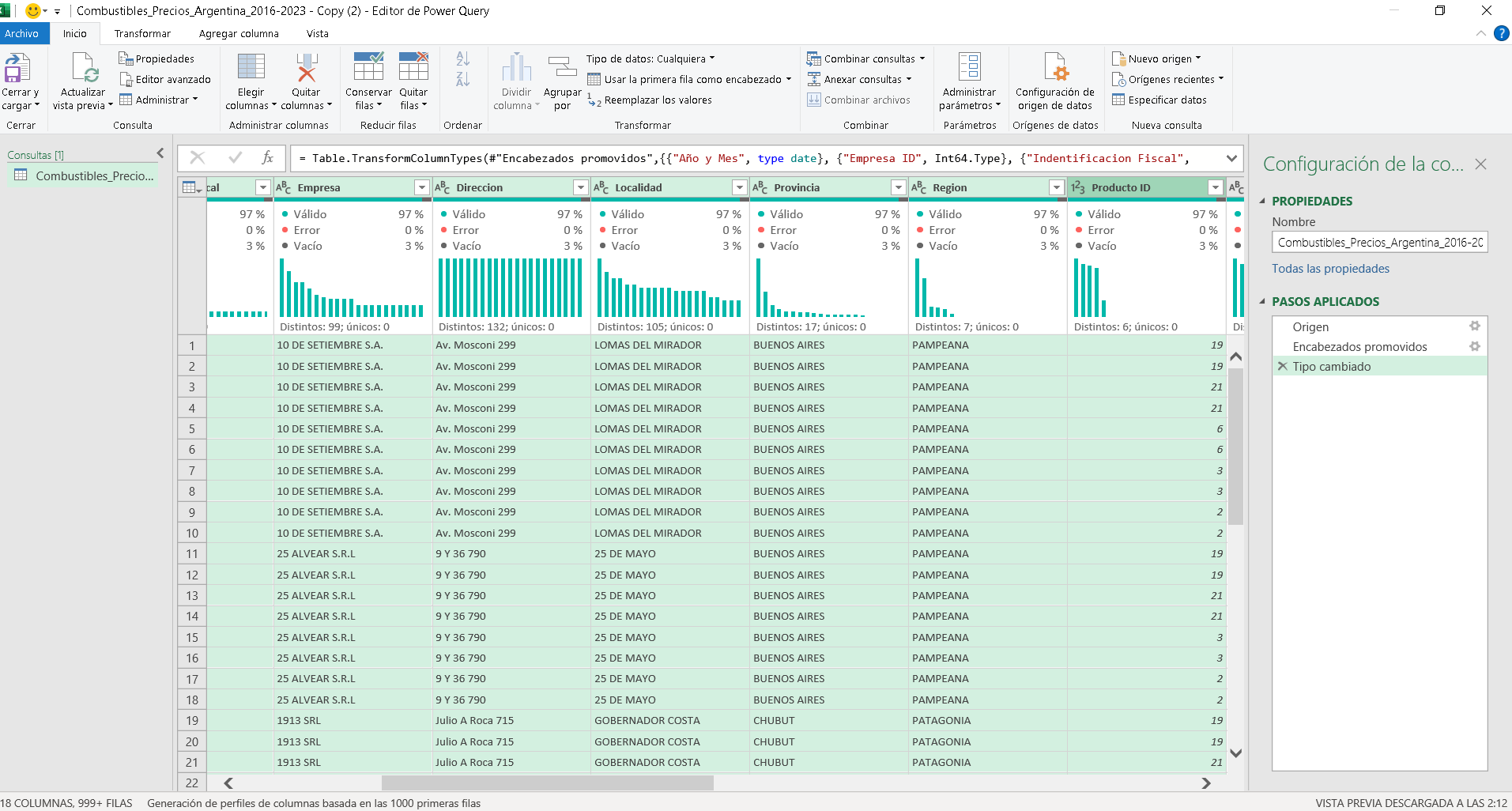
Como podemos ver, tenemos 18 columnas y en todas tenemos vacíos. Pasamos a eliminarlos en una de estas columnas, por ejemplo, en precio, porque si filtramos por los nulos de precio, todas las demás columnas tienen vacíos (Imagen 4).  Esto quiere decir que podemos utilizar esta para eliminar los vacíos. Hagámoslo. El resultado es que en las demás columnas los datos no están vacíos; se encuentran bien (Imagen 5).
Esto quiere decir que podemos utilizar esta para eliminar los vacíos. Hagámoslo. El resultado es que en las demás columnas los datos no están vacíos; se encuentran bien (Imagen 5).
Pero ahora surge otro detalle: en latitud siguen existiendo vacíos. Bueno, vamos a ello, filtremos los datos únicos que están vacíos (Imagen 6).
Efectivamente, como podemos ver, tenemos la latitud vacía (Imagen 7).
Ahora bien, seleccionamos empresa, dirección, localidad y región, observando que para ambos casos en vacío hay dos registros. Si filtramos por estos criterios, podemos obtener la latitud y aplicar alguna técnica para el nulo por la latitud (En este caso, aplicando la técnica eliminación por no afectar el análisis de datos, solo dos registros, no representan un impacto sobre el análisis general). Dado que eliminar registros, lo podemos hacer si la cantidad de registros con valores faltantes es pequeña en comparación con el tamaño total del conjunto de datos y no son significativos para tu análisis, puedes optar por eliminar esos registros. Tenemos un total de 34753 registros quitando los vacíos de precios y quitando los vacíos de latitud , y son solo dos vacíos, para ese caso eliminados. En esta fase solo hemos identificado los vacíos y eliminado los que no nos hacen falta, dado que no podríamos aplicar los criterios de los 2 tipos de imputaciones:
Imputación simple: Puedes reemplazar los valores faltantes con un valor específico, como la media, la mediana o la moda de la columna correspondiente.
Imputación avanzada: Utiliza técnicas más avanzadas, como la imputación basada en modelos (por ejemplo, regresión o k-vecinos más cercanos) para predecir los valores faltantes en función de otras variables.
Continuando con la limpieza vamos a la fase dos, estandarizar criterios categóricos:
Estandarizar la columna empresa: Este caso está super interesante de estandarizar, dado que existen discrepancias relevantes en los nombres de las empresas.
Para realizar este paso, primero, crearemos un código en Python para normalizar los nombres de las empresas. Imagen 8
Claro, aquí tienes una explicación detallada del código:
- Importación de bibliotecas:
– `import pandas as pd`: Importa la biblioteca panda y la renombra como pd para facilitar su uso.
– `from fuzzywuzzy import fuzz`: Importa la función `fuzz` del paquete `fuzzywuzzy`, que se utilizará para calcular la similitud entre cadenas de texto.
- Cargar el archivo de datos:
– `ruta_archivo = «ruta_del_archivo.csv»`: Establece la ruta del archivo CSV que contiene los datos.
– `data = pd.read_csv(ruta_archivo)`: Utiliza la función `read_csv` de pandas para cargar los datos del archivo CSV en un DataFrame llamado `data`.
- Definir la función de cálculo de similitud:
– `def calcular_similitud(nombre1, nombre2)`: Define una función llamada `calcular_similitud` que toma dos cadenas de texto como entrada y devuelve la similitud entre ellas utilizando la función `token_sort_ratio` de `fuzzywuzzy`.
- Inicializar una lista de resultados:
– `resultados = []`: Crea una lista vacía llamada `resultados` para almacenar los resultados del cálculo de similitud.
- Bucle para calcular la similitud entre cada par de empresas:
– `for i, empresa_evaluada in enumerate(data[‘Empresa’]):`: Itera sobre cada empresa en la columna ‘Empresa’ del DataFrame `data`.
– `similitudes_empresa_evaluada = []`: Inicializa una lista vacía para almacenar las similitudes de la empresa evaluada con otras empresas.
– `for j, otra_empresa in enumerate(data[‘Empresa’]):`: Itera sobre cada otra empresa en la columna ‘Empresa’ del DataFrame `data`.
– `if i != j:`: Comprueba si la empresa evaluada es diferente de la otra empresa para evitar comparaciones consigo misma.
– `similitud = calcular_similitud(empresa_evaluada, otra_empresa)`: Calcula la similitud entre la empresa evaluada y la otra empresa utilizando la función `calcular_similitud` definida anteriormente.
– `similitudes_empresa_evaluada.append({‘Empresa evaluada’: empresa_evaluada, ‘Empresa similar’: otra_empresa, ‘Similitud’: similitud})`: Añade un diccionario con la empresa evaluada, la otra empresa y la similitud calculada a la lista `similitudes_empresa_evaluada`.
– `resultados.extend(similitudes_empresa_evaluada)`: Agrega las similitudes calculadas para la empresa evaluada a la lista de resultados.
- Convertir los resultados a un DataFrame:
– `resultados_df = pd.DataFrame(resultados)`: Convierte la lista de resultados en un DataFrame llamado `resultados_df`.
- Guardar los resultados en un archivo CSV:
– `ruta_resultados = ruta_archivo.replace(‘.csv’, ‘_resultados.csv’)`: Modifica la ruta del archivo original para crear una nueva ruta para el archivo de resultados CSV.
– `resultados_df.to_csv(ruta_resultados, index=False)`: Guarda el DataFrame de resultados en un archivo CSV en la ruta especificada sin incluir el índice de fila.
- Imprimir un mensaje de confirmación:
– `print(«Resultados guardados en:», ruta_resultados)`: Imprime un mensaje indicando la ubicación donde se guardaron los resultados.
Este código carga los datos del archivo CSV, calcula la similitud entre cada par de empresas en la columna ‘Empresa’, almacena los resultados en un nuevo DataFrame y guarda los resultados en un nuevo archivo CSV.
Para este procesos tenemos ratio, partial.ratio, token_sort_ratio, y toke_set_ratio, en este caso usamos primero token_sort_ratio
Pero en este caso, como es un reto de datos y no existe este punto de control, creamos la maestra correcta con la información de cruce adecuada. Tomaremos los que son por corregir desde el rango de similitud >= a 85 y manualmente en el CSV resultante edito los nombres que, bajo mi criterio, son los adecuados. Presentamos casos con los siguientes escenarios por evaluar:
Podremos encontrar resultados como:
Exacta Coincidencia: Donde la «Empresa Evaluada» y la «Empresa Similar» son exactamente iguales.
Ejemplo: «AGROPETROLERA CHAJARI S.R.L.» y «AGROPETROLERA CHAJARI S.R.L.» tienen una similitud del 95%, y se cumple la condición.
Coincidencia Parcial: Donde las empresas tienen similitudes significativas pero no son exactamente iguales.
Ejemplo: «ALONSO CONSTANTINO RAUL» y «CONSTANTINO RAUL ALONSO» tienen una similitud del 100%, y se cumple la condición.
Coincidencia Parcial con Variaciones: Donde las empresas tienen similitudes, pero también hay variaciones en los nombres.
Ejemplo: «AGRICULTORES FEDERADOS ARGENTINOS» y «AGRICULTORES FEDERADOS ARGENTINOS MACIEL» tienen una similitud del 90%, pero no cumplen la condición.
Errores Tipográficos: Donde las diferencias se deben a errores tipográficos o caracteres especiales.
Ejemplo: «AUTOMÓVIL CLUB ARGENTINO» y «AUTOMOVIL CLUB ARGENTINO» tienen una similitud del 98%, y no cumplen la condición.
Inversiones de Palabras: Donde las palabras en las empresas se invierten o cambian de orden.
Ejemplo: «ARBIZU Y PAGELLA S.R.L.» y «PAGELLA Y ARBIZU S.H.» tienen una similitud del 90%, y se cumple la condición.
Variaciones de Abreviaturas: Donde las diferencias se deben a abreviaturas o formatos diferentes.
Ejemplo: «AUTOSUR RÍO GRANDE S.A. (APIES 1886)» y «AUTOSUR RIO GRANDE SA.» tienen una similitud del 97%, y se cumple la condición.
Diferencias de Puntuación: Donde las diferencias se deben a la presencia o ausencia de puntuación.
Ejemplo: «BARBERO HERMANOS S.A.» y «BARBIERI HERMANOS S.A.» tienen una similitud del 93%, pero no cumplen la condición.
Estos son solo algunos ejemplos de los diferentes tipos de casos que puedes encontrar al comparar empresas en base a su similitud. Dependiendo de tus criterios específicos y del contexto del análisis, es posible que desees manejar cada tipo de caso de manera diferente
Imagen 9

Ahora la lógica para realizar el proceso estándar es crear la columna que sera estandariza y la columna que será manipulada, es decir la original la dejamos para poder realizar el cruce en power query , con consultas.
Aterrizamos el fichero original, en un nuevo Excel y el fichero que nos devuelve los resultados de Python
Se filtro por las opciones que primero la columna similitud es mayor a >=90 y luego de una revisión manual, considere para el cambio o no, tú puedes ajustar el código a tu criterio o , puedes perfeccionarlo puedes utilizar el procesamiento del lenguaje natural (NLP) para optimizar este proceso de comparación y ajuste de nombres de empresa.
En total son 534 filas obtenidas con diferencias.
Pero recordemos que se realizara la revisión manual , de los 534 filas de las cuales si se modificaran , ya es cuestión de que se revisen manualmente , y poder manejar diferentes opciones. (Yo en mi caso solo modifique algunas no todas )
Posterior a ello, luego de tener Estandarizado los nombres, de empresa es bueno empaparse de la data set, como lo hago en mi caso.
Realizare el cruce, en una columna condicionada en power query , con mi maestro de empresas estandarizado, cree la nueva columna empresa.
Primero en un Excel nuevo lo que hacemos es conectarnos a ambos orígenes como el data set y el csv originado del Python.
Luego de ello creamos una consulta de combinar por el campo clave Empresa y en nuestro nuevo CSV empresa evaluada, imagen 10.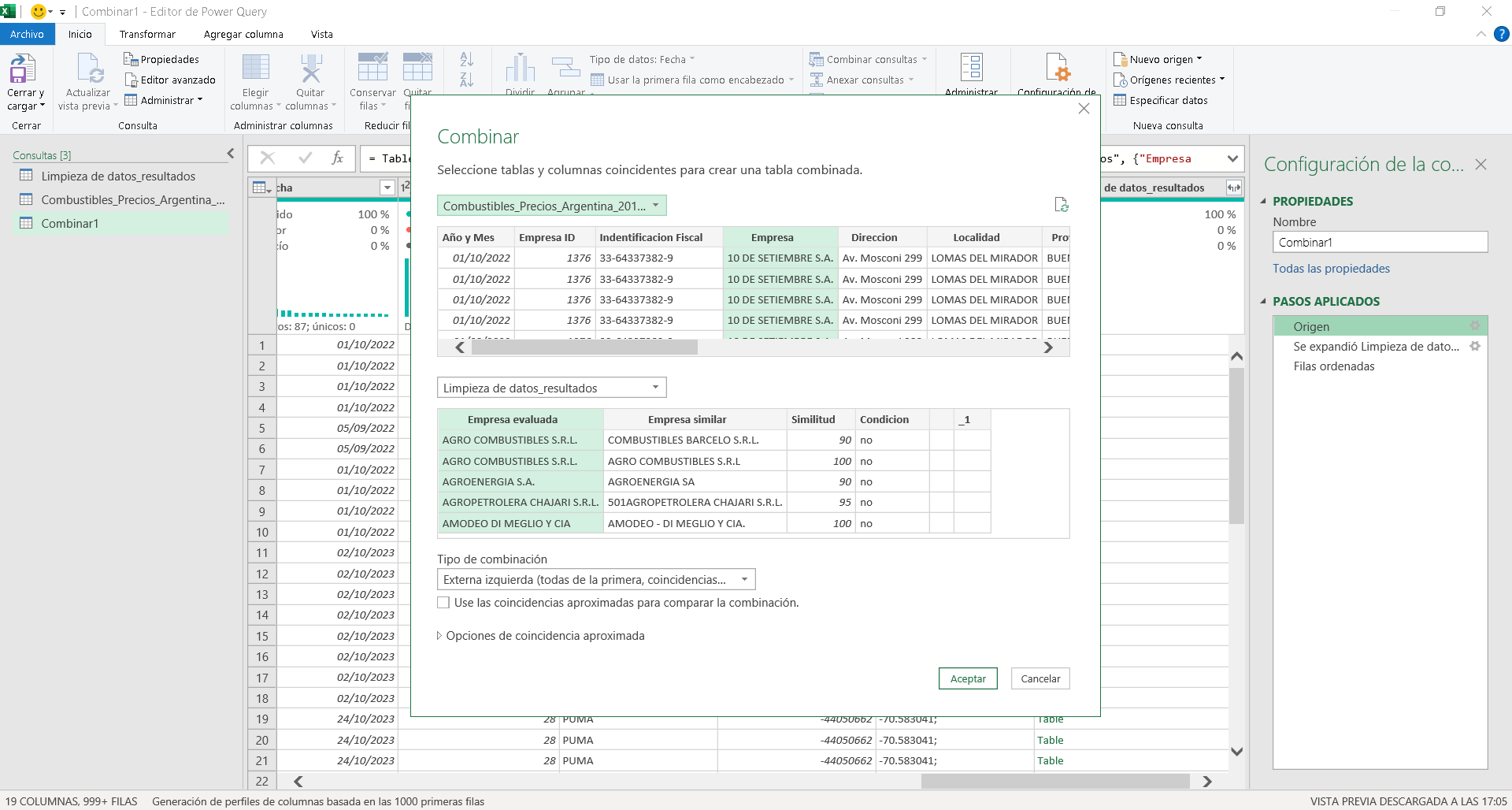
Luego de ello extraemos en la nueva consulta dos columnas, condicional que nos indica cual esta evaluada y la columna empresa similar imagen 11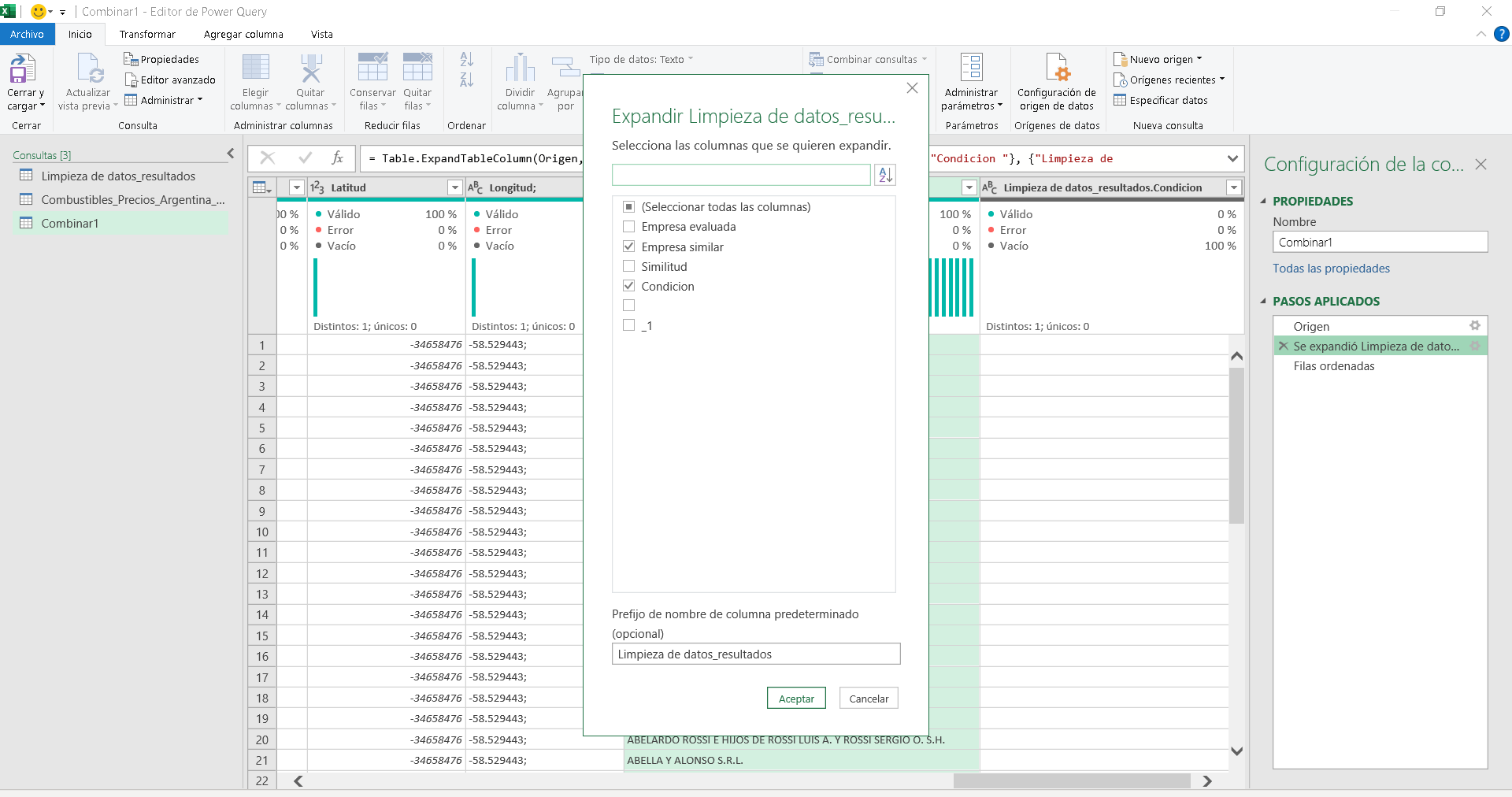
Pasamos a crear una columna condicional nueva para la empresa, con el operador lógico if, cuando condicional sea si, columna Empresa similar, cuando empresa sea no o vacía empresa. Imagen 12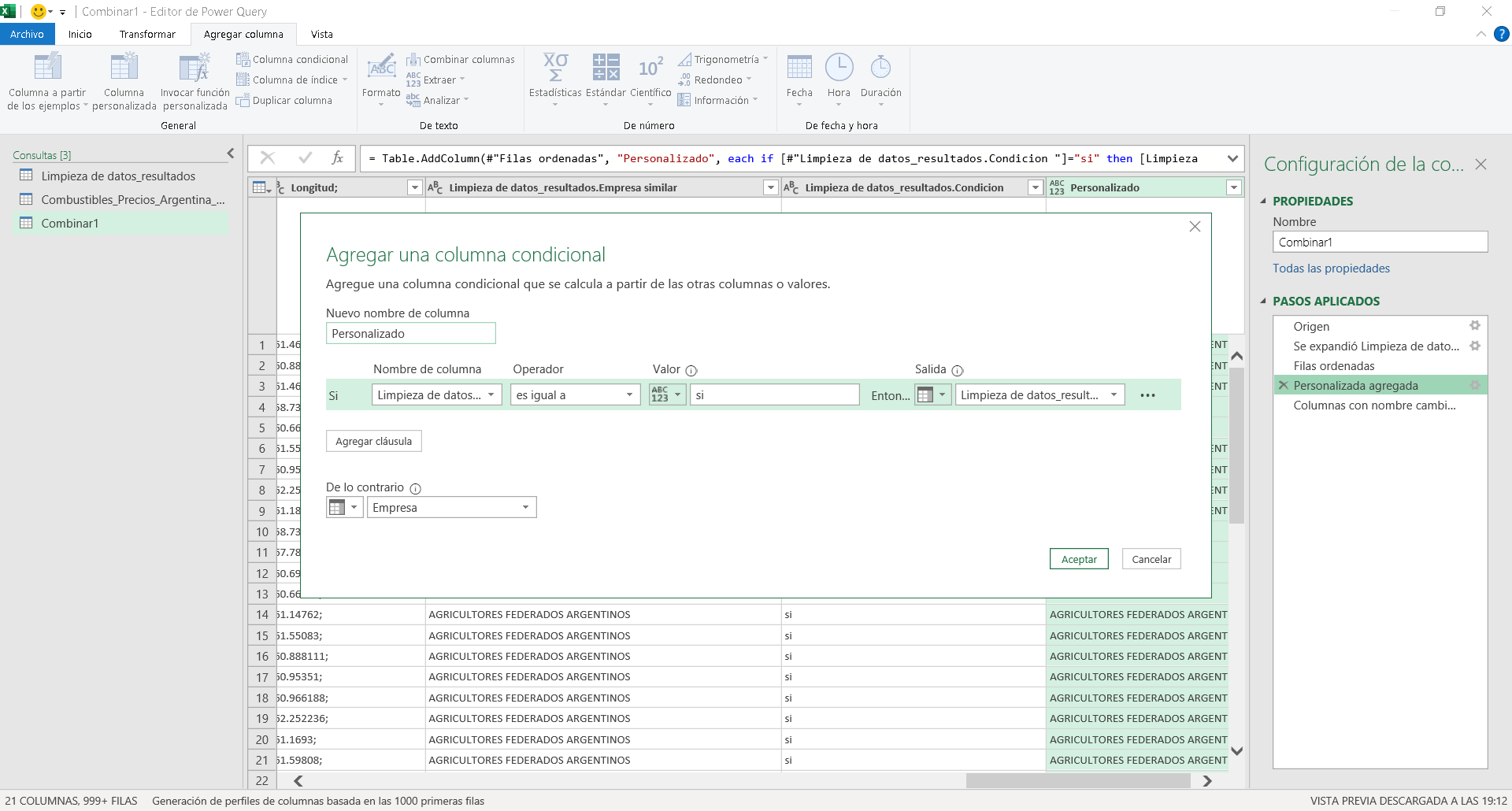
Eliminamos las columnas de mas y las columnas nuevas, con estos procesos tendríamos nuestra tabla con los estándares de nombres de empresa ajustado (Recuerda que puedes mover el número de similitud más bajo y encontrar muchas más diferencias.)
Imagen 13

Ahora para empaparnos, más de este data set, podemos sumas más modificaciones y análisis, de nivel básico para entender como este compuesto
Empiezo a calcular, por ejemplo, el maximo, mínimo, promedio de mis datos aditivos interesantes, en este caso es el precio,
Tienes dos opciones para hacer esto con medidas manual mente con columnas, o específicamente con, tablas dinámicas, lo realizare con tablas dinámicas
por qué selecciono el precio para obtener la lógica del dato y así manejar eficientemente los datos con gestión valida y eficiente dado que las 17 preguntas que tenemos en el reto de datos va un poco entorno a los datos cuantitativos. Imagen imagen 14
Con esto sabemos el mínimo le maximo, el promedio, la cantidad de registros que tiene nuestro data set.
| Cuenta de Precio | Suma de Precio2 | Mín. de Precio | Máx. de Precio3 | Promedio de Precio |
| 34753 | 1118390318 | 700 | 75000 | 32181 |
Vamos enamorándonos de nuestros datos.
Cantidad de empresas, OJITO que esto fue con los cambios aplicados por la estandarización de Python y el ajuste manual con la tabla madre.
Pero la idea es tener un conteo distintivo de cada dato categórico como lo vemos en la imagen 15.
| Recuento distinto de Empresa | Recuento distinto de Direccion | Recuento distinto de Localidad | Recuento distinto de Provincia | Recuento distinto de Region |
| 3334 | 4389 | 1045 | 24 | 6 |
Con este pequeño análisis, limpieza y valoración podemos ir entendiendo de que va nuestro data set , comprenderlo , para luego crear el modelo de datos , contestar las preguntas de negocio y crear nuestro dashboard.
En conclusión, este artículo ofrece un enfoque detallado y personalizado para llevar a cabo la evaluación y limpieza de datos utilizando herramientas como Excel, Power Query y Python. Se destaca la importancia de este proceso en la era de la información, donde los datos son activos valiosos para empresas y organizaciones.
El artículo guía a través de varios pasos fundamentales en el proceso de limpieza de datos, comenzando por el manejo de valores faltantes y la evaluación de su impacto en el análisis. Se muestra cómo identificar y eliminar los valores faltantes de manera efectiva, así como la importancia de decidir entre técnicas de imputación o eliminación según el contexto del análisis.
Además, se aborda la estandarización de criterios categóricos, específicamente el caso de normalización de los nombres de empresas. Se presenta un enfoque práctico utilizando Python para calcular la similitud entre nombres de empresas y estandarizarlos según criterios específicos. Se describen varios escenarios de coincidencia entre nombres de empresas y se muestra cómo manejar cada caso de manera efectiva.
Finalmente, el artículo resalta la importancia de comprender en profundidad el conjunto de datos mediante análisis adicionales, como calcular estadísticas descriptivas y contar la cantidad de empresas distintas en el conjunto de datos. Esto proporciona una base sólida para futuros pasos, como la creación de modelos de datos y la generación de insights para la toma de decisiones empresariales.
Link GitHub: https://github.com/vicente2121/Fase_Estandar_reto_14/blob/main/README.md
Vicente Antonio Juan Magallanes.


![]()


