
¡Bienvenidos, muy buenos días tardes o noches , según donde me leas !
Uniéndonos al reto de datos, en este caso es especial, dado que utilizaremos una cuenta de Zoom Charts para poder utilizar los objetos visuales de este reto. Lo primero será acceder al conjunto de datos al cual deseamos participar. Buscamos la siguiente URL: https://zoomcharts.com/en/microsoft-power-bi-custom-visuals/challenges/fp20analytics-october-2023, en la cual nos proporciona un formulario para rellenar y obtener la cuenta y la contraseña con la licencia para usar en este reto (imagen 3)
https://zoomcharts.com/en/microsoft-power-bi-custom-visuals/challenges/fp20analytics-october-2023, en la cual nos proporciona un formulario para rellenar y obtener la cuenta y la contraseña con la licencia para usar en este reto (imagen 3)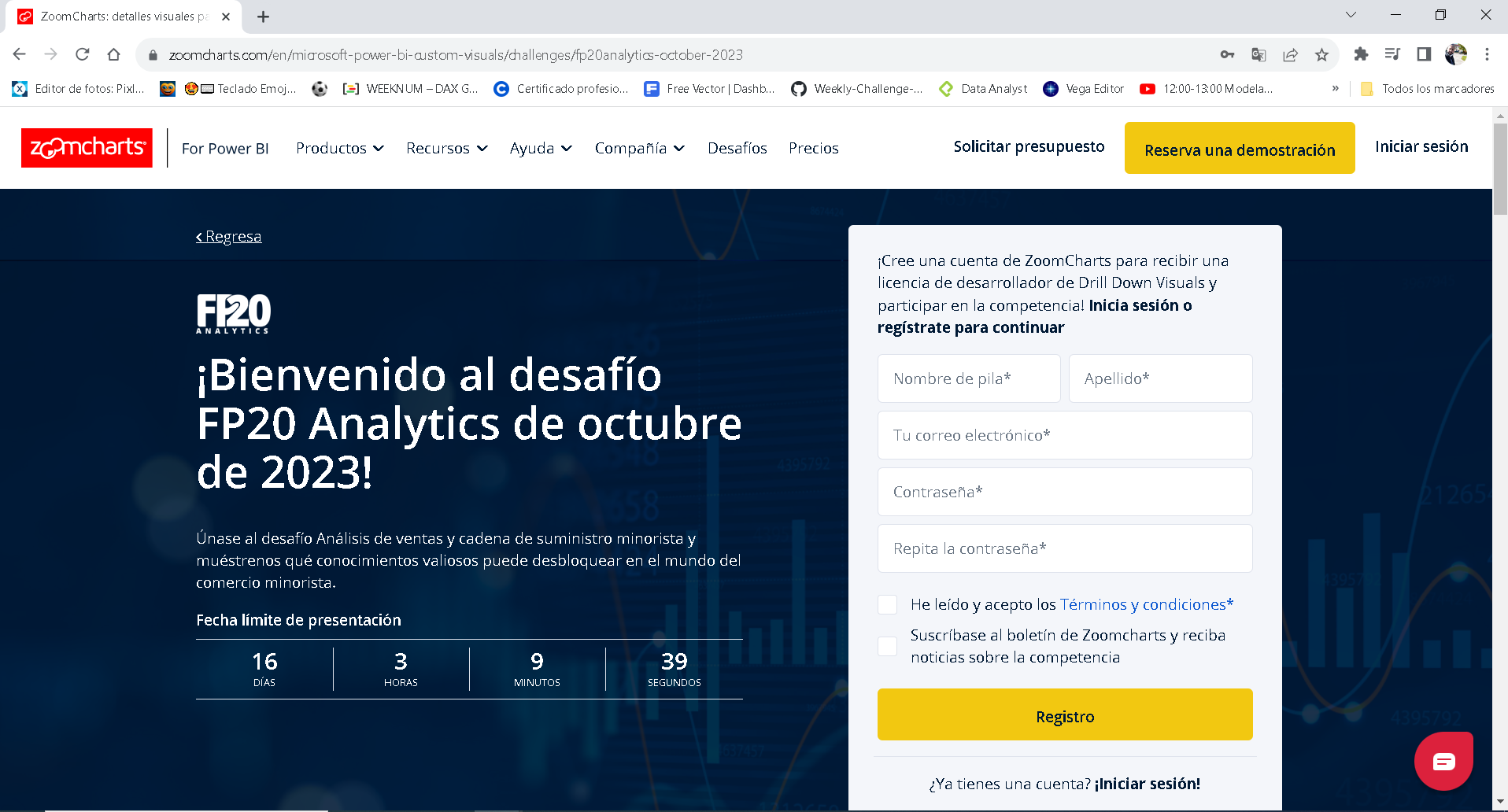 .
.
Luego de rellenar el contenido, aparecerá una ventana emergente en la cual no solicitará específicamente dar check para activar nuestra cuenta (imagen 2)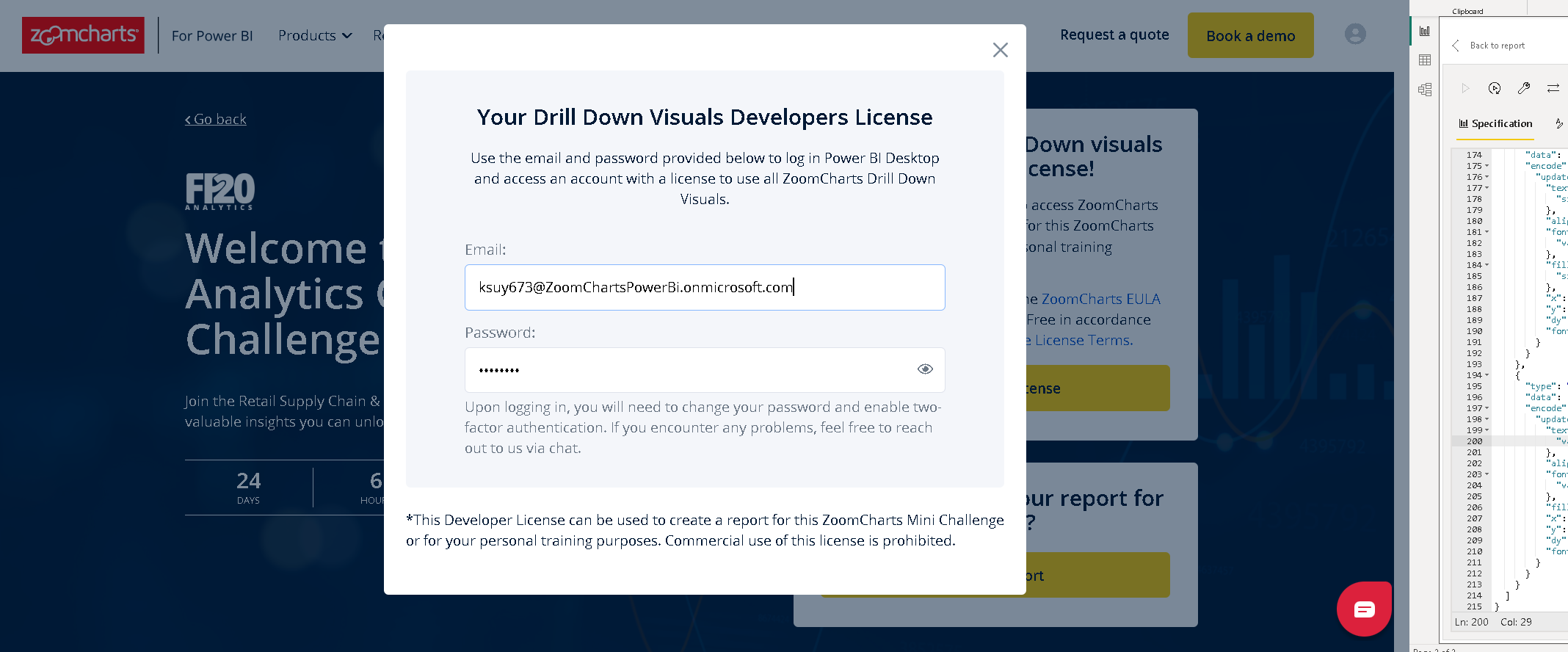 . Nos devolverá nuestra cuenta y la contraseña para ser utilizadas en el reto de datos (imagen 3 -).
. Nos devolverá nuestra cuenta y la contraseña para ser utilizadas en el reto de datos (imagen 3 -).
Posteriormente, bajando un poco más, encontramos el resumen en el cual se nos hacen las preguntas clave de negocio a desarrollar y específicamente los datos que necesitamos responder, así como más información relevante como fecha, hora y más contenido (imagen 4).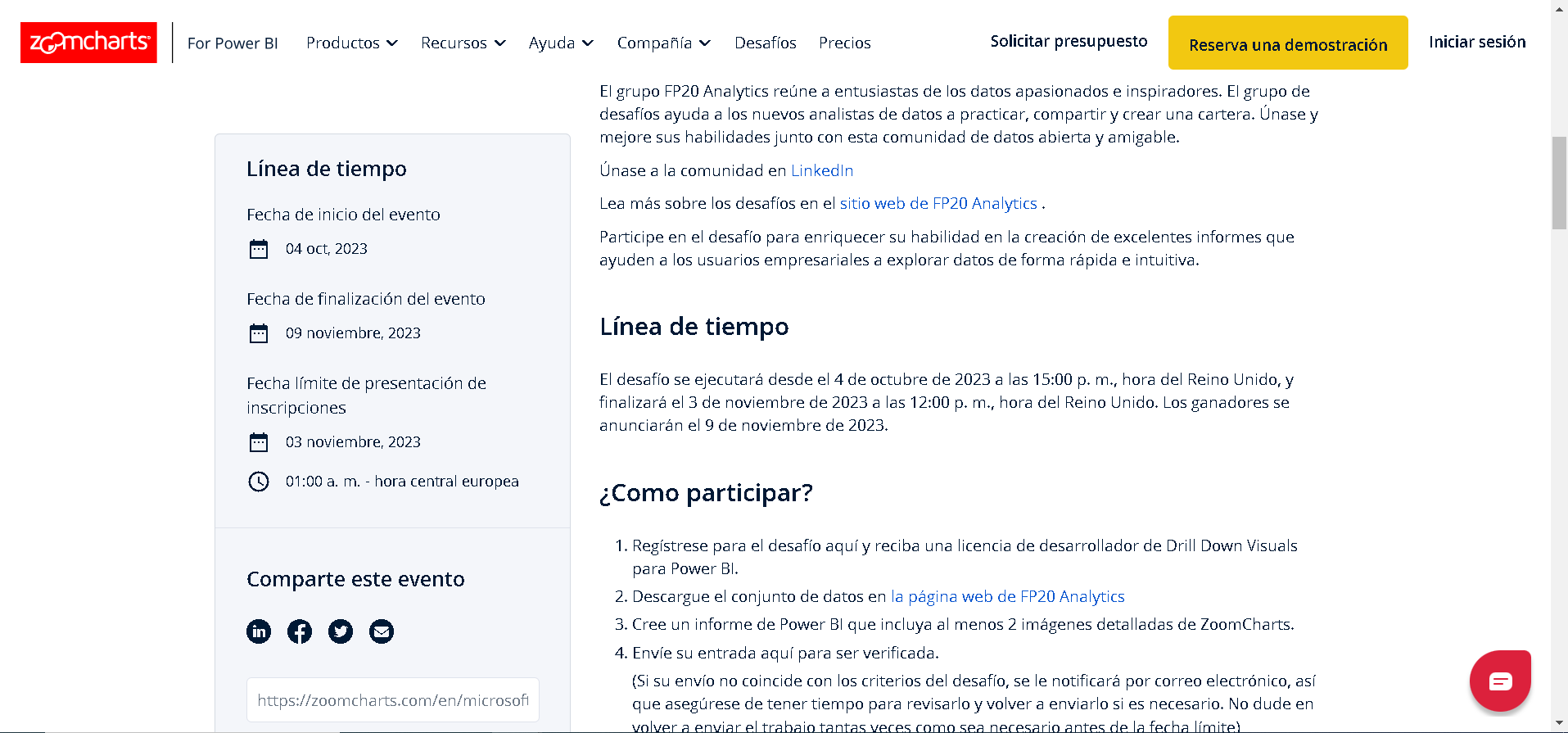
Para descargar específicamente el conjunto de datos, accedemos a la siguiente URL: https://fp20analytics.com/challenges (imagen 5).
Analizando primero el dataset que nos proporcionan, lo primero y más fundamental es un archivo XLSX con dos hojas: una con los datos y una tabla de calendario lista para usar.
Ahora importemos estos datos para comenzar lo bueno y el desarrollo que vale la pena. Primero, como siempre, el modelo y más modelo de datos. Pero antes, activaremos nuestra cuenta para usar las visualizaciones de ZoomCharts. Primero, hacemos clic en donde dice «Sign In» en la parte superior derecha (imagen 7)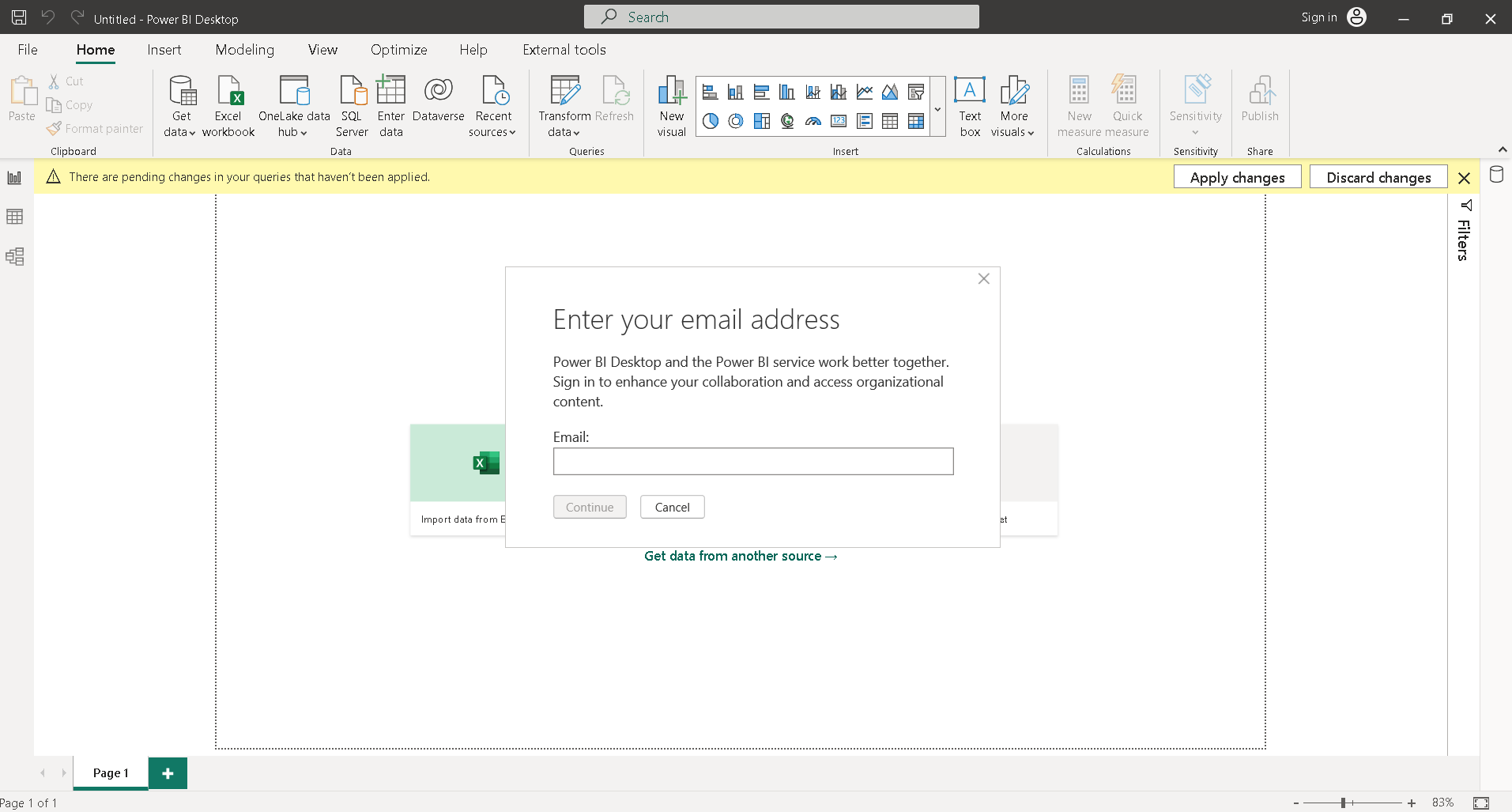 . Pegamos el correo que nos dieron en el registro de Zoom Charts. Luego, hacemos clic donde dice (imagen 8)
. Pegamos el correo que nos dieron en el registro de Zoom Charts. Luego, hacemos clic donde dice (imagen 8)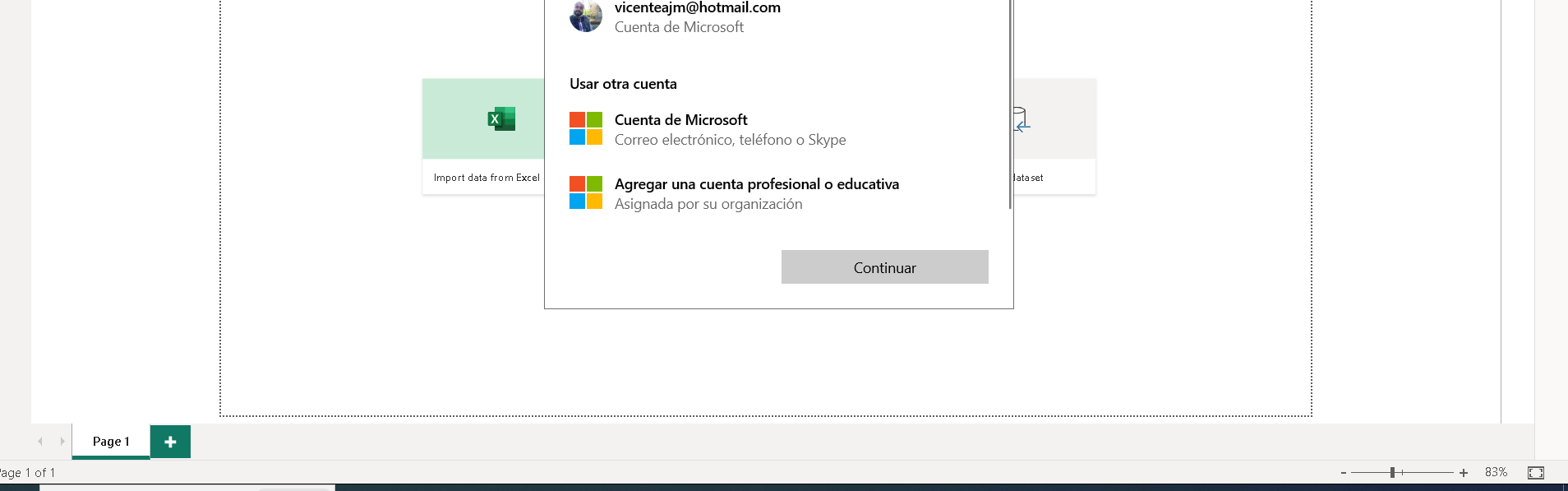 . Agregamos los datos y colocamos la contraseña (imagen 9)
. Agregamos los datos y colocamos la contraseña (imagen 9) . Ahora seleccionamos «Siguiente» para continuar (imagen 10)
. Ahora seleccionamos «Siguiente» para continuar (imagen 10)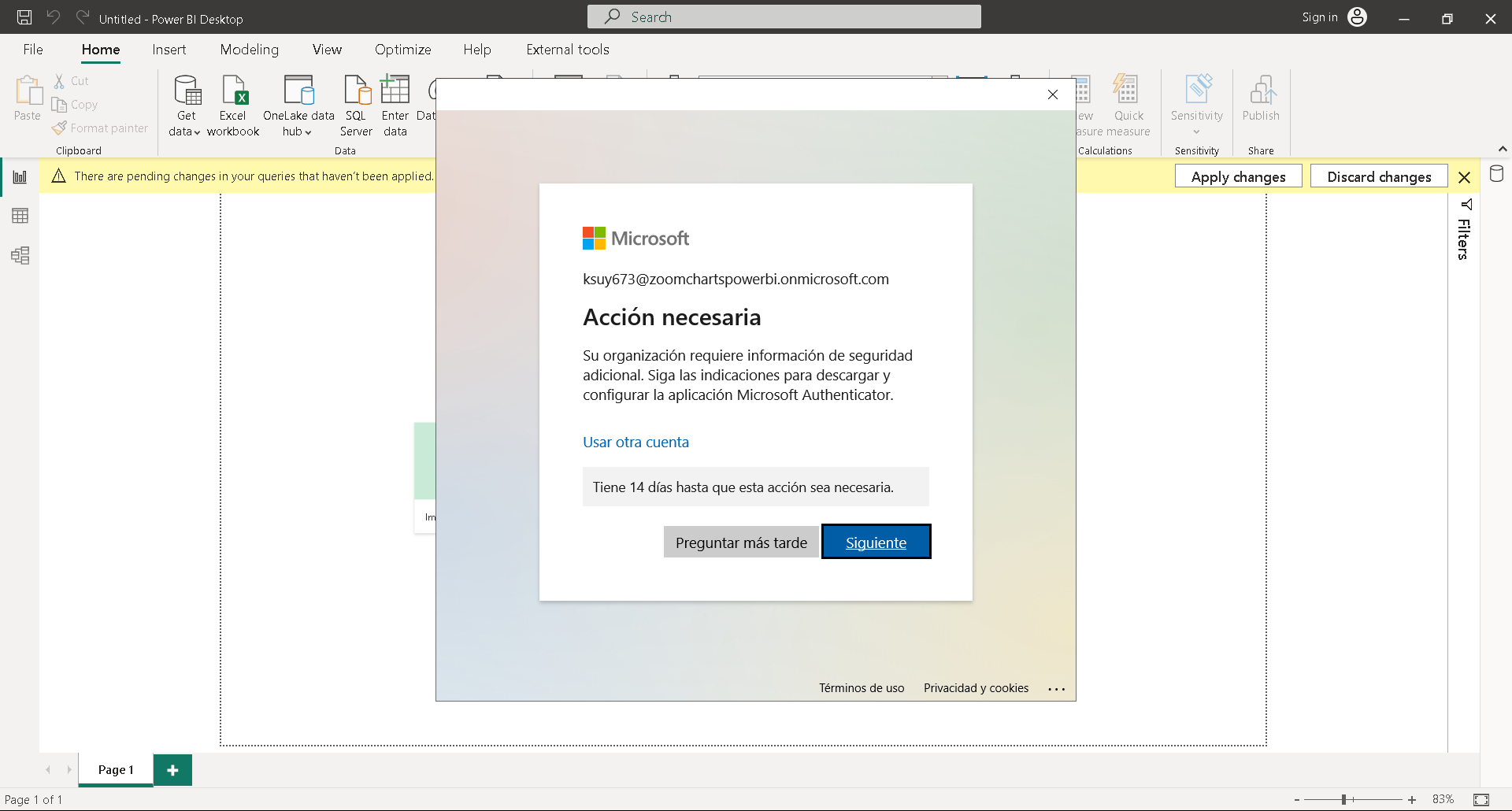 . Con estos pasos, tenemos activa la cuenta y procedemos a descargar específicamente.
. Con estos pasos, tenemos activa la cuenta y procedemos a descargar específicamente.
Luego, accedemos a la tienda de visualizaciones de Power BI y damos clic en «Get More Visuals» para que aparezcan todas las visualizaciones. Abrimos y cerramos nuestro reporte, y como se muestra en la imagen, al volverlo a abrir, tenemos todas las visualizaciones geniales que nos brinda ZoomCharts (imagen 12).
En mi opinión, siempre es más divertido crear las tablas calendario, ya sea en Power Query o en DAX, pero puedes usar la compartida. Para la tabla de hechos, debemos editarla manualmente dado que existen varias dimensiones para crear. La primera será Cliente o Customer, y este mismo tiene un ID (imagen 13)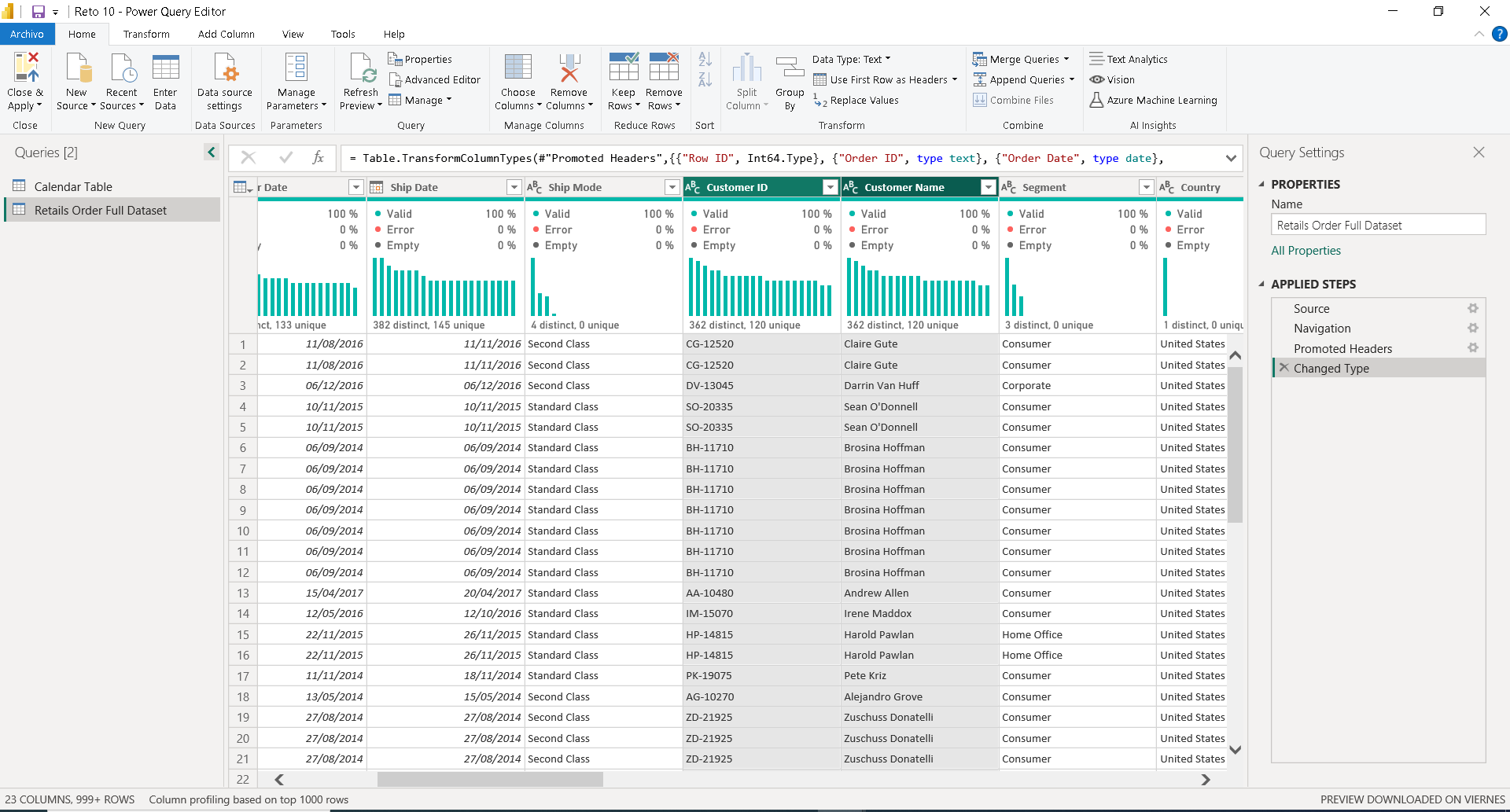 . Todo el modelado de datos lo realizaremos con Power Query. Recordemos primero crear un duplicado de la principal. Luego de esto, limpiamos la data completa en nuestros registros y eliminamos duplicados, usando como clave foránea la clave de negocio proporcionada (imagen 14).
. Todo el modelado de datos lo realizaremos con Power Query. Recordemos primero crear un duplicado de la principal. Luego de esto, limpiamos la data completa en nuestros registros y eliminamos duplicados, usando como clave foránea la clave de negocio proporcionada (imagen 14).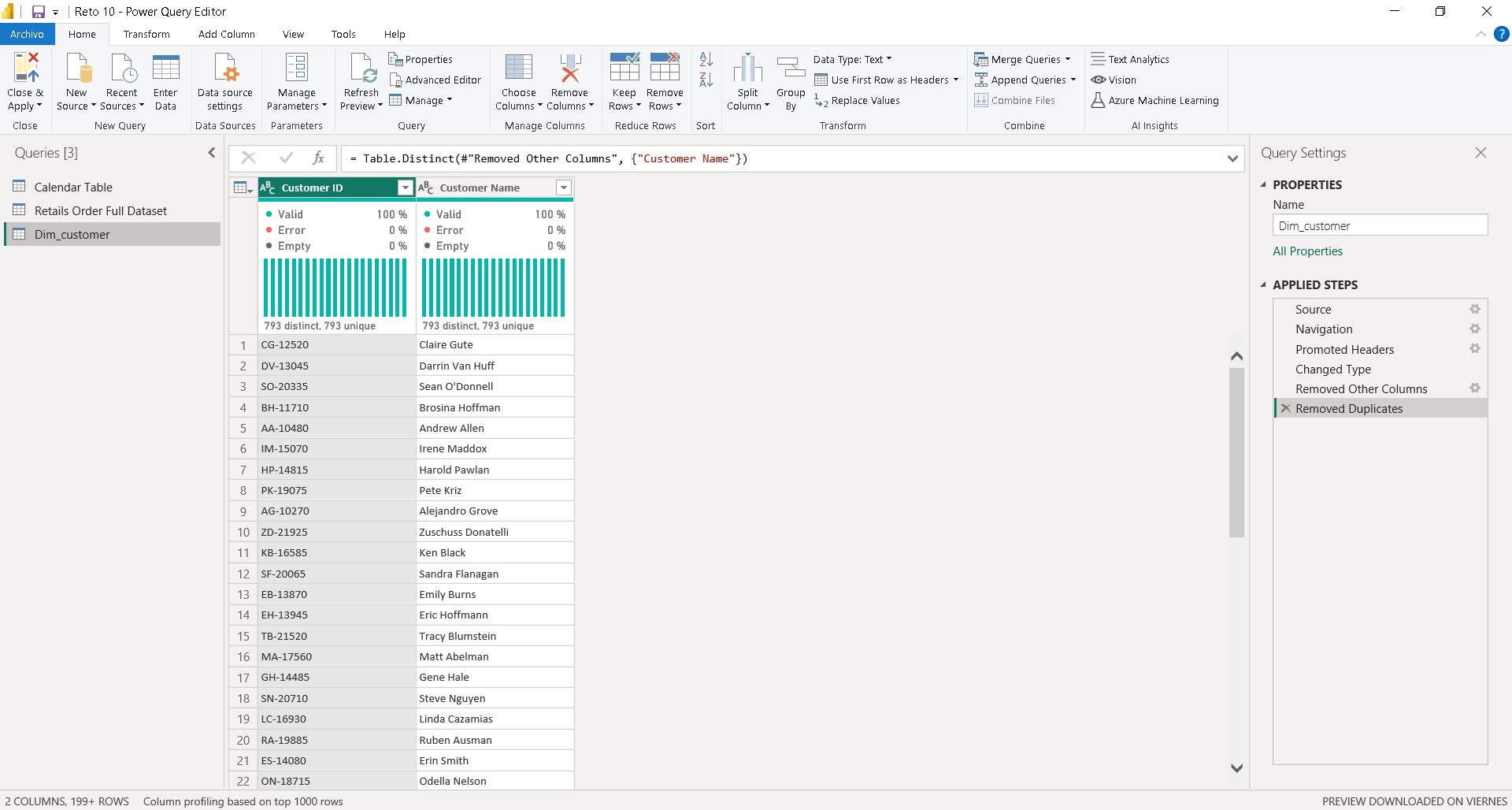
Ahora, después de ver todos estos pasos, vamos a crear un modelo de datos bonito y eficiente.
Identificación de Dimensiones Relevantes
En este punto, es fácil identificar dos dimensiones clave: «Customer» y «Segment». Sin embargo, la dimensión que resulta particularmente interesante es «País», debido a sus diferentes niveles de granularidad, como se ilustra en la imagen 15 . Para eliminar los duplicados sin perder datos, debemos identificar el nivel de granularidad más apropiado dentro de esta dimensión.
. Para eliminar los duplicados sin perder datos, debemos identificar el nivel de granularidad más apropiado dentro de esta dimensión.
La Importancia de la Granularidad
La granularidad se refiere al nivel de detalle de los datos almacenados en una base de datos dimensional. Esta elección de diseño es fundamental ya que afecta tanto al tamaño de la base de datos como a la naturaleza de las preguntas que se pueden responder utilizando dicha base de datos.
Tipos de Granularidad
- Granularidad Fina (Alta Granularidad): En este nivel, los datos se almacenan con el máximo detalle posible. Por ejemplo, en una base de datos de ventas, podría incluir detalles de cada transacción individual, como ID de la transacción, ID del cliente, ID del producto, fecha y hora exactas de la transacción, cantidad vendida, precio unitario, total de la transacción e ID del empleado que realizó la venta.
- Granularidad Media: En este nivel, los datos se consolidan a un nivel intermedio. En el caso de una base de datos de ventas, la granularidad media podría representar ventas diarias por producto o ventas diarias por tienda.
- Granularidad Gruesa (Baja Granularidad): Aquí, los datos se consolidan aún más. Por ejemplo, en una base de datos de ventas, la granularidad gruesa podría implicar ventas mensuales o anuales por tienda o incluso ventas anuales por región o país.
Implicaciones de la Elección de Granularidad
La elección de la granularidad tiene varias implicaciones importantes:
- Tamaño de la Base de Datos: Una granularidad más fina resultará en una base de datos más grande debido a la inclusión de más detalles. Esto puede afectar los costos de almacenamiento y el rendimiento de las consultas.
- Flexibilidad de Consulta: Una granularidad más fina permite responder preguntas más detalladas, mientras que una granularidad más gruesa limita la capacidad de responder a preguntas específicas.
- Complejidad de ETL: Una granularidad más fina puede aumentar la complejidad del proceso de Extracción, Transformación y Carga (ETL) debido a la necesidad de procesar y fusionar más datos.
Consideraciones al Elegir la Granularidad
Al elegir la granularidad, es fundamental considerar:
- Los requisitos de los usuarios finales y las preguntas que desean responder.
- El volumen esperado de datos y su impacto en el almacenamiento y el rendimiento.
- La disponibilidad de fuentes de datos que proporcionen el nivel de detalle deseado.
- La necesidad de optimizar el rendimiento de la base de datos en consultas de alta granularidad.
Esta comprensión de la granularidad es esencial para tomar decisiones informadas en el modelado de datos.
Importancia de la Elección de la Granularidad
La elección de la granularidad representa un delicado equilibrio entre la capacidad de responder a preguntas detalladas y las limitaciones prácticas relacionadas con costos, almacenamiento y rendimiento. Esta decisión desempeña un papel crítico en el diseño de cualquier base de datos dimensional.
Aplicación en el Ejemplo
En nuestro ejemplo, nos enfrentamos a cinco columnas relacionadas con la dimensión «Country» (País), cada una con un nivel de granularidad diferente. Es esencial considerar esta variabilidad al eliminar duplicados, para asegurarnos de mantener un orden jerárquico y no perder registros innecesariamente.
Observaciones sobre la Granularidad
- Country (País): Esta columna representa una granularidad gruesa, ya que los países son divisiones geográficas de alto nivel.
- Region: Similar al país, esta columna también tiene una granularidad gruesa, ya que las regiones pueden agrupar varios estados o ciudades dentro de un país.
- State (Estado): La granularidad de esta columna es media, ya que los estados son subdivisiones dentro de un país, pero más generales que las ciudades o códigos postales.
- City (Ciudad): La columna «City» es más detallada que la de estado, pero aún se mantiene en un nivel de granularidad medio, ya que dentro de una ciudad pueden existir diferentes códigos postales.
- Postal Code (Código Postal): Esta columna tiene la granularidad más fina, ya que los códigos postales representan divisiones geográficas muy específicas, generalmente áreas pequeñas dentro de una ciudad.
Dado que estamos diseñando una dimensión geográfica llamada «Country» en un modelo de datos dimensional, estas columnas podrían formar una jerarquía de granularidad, que va desde la más gruesa (País) hasta la más fina (Código Postal).
Proceso en Power Query
En Power Query, eliminaremos la columna de «Código Postal» (Cuidado, aquí hay una trampa, pero la mostraré a propósito, ver imagen 15
).
Luego, para comprobar que no hemos perdido datos esenciales al eliminar solamente por «Código Postal», realizaremos un «merge» con la tabla principal o tabla de hechos, como se ilustra en la imagen 17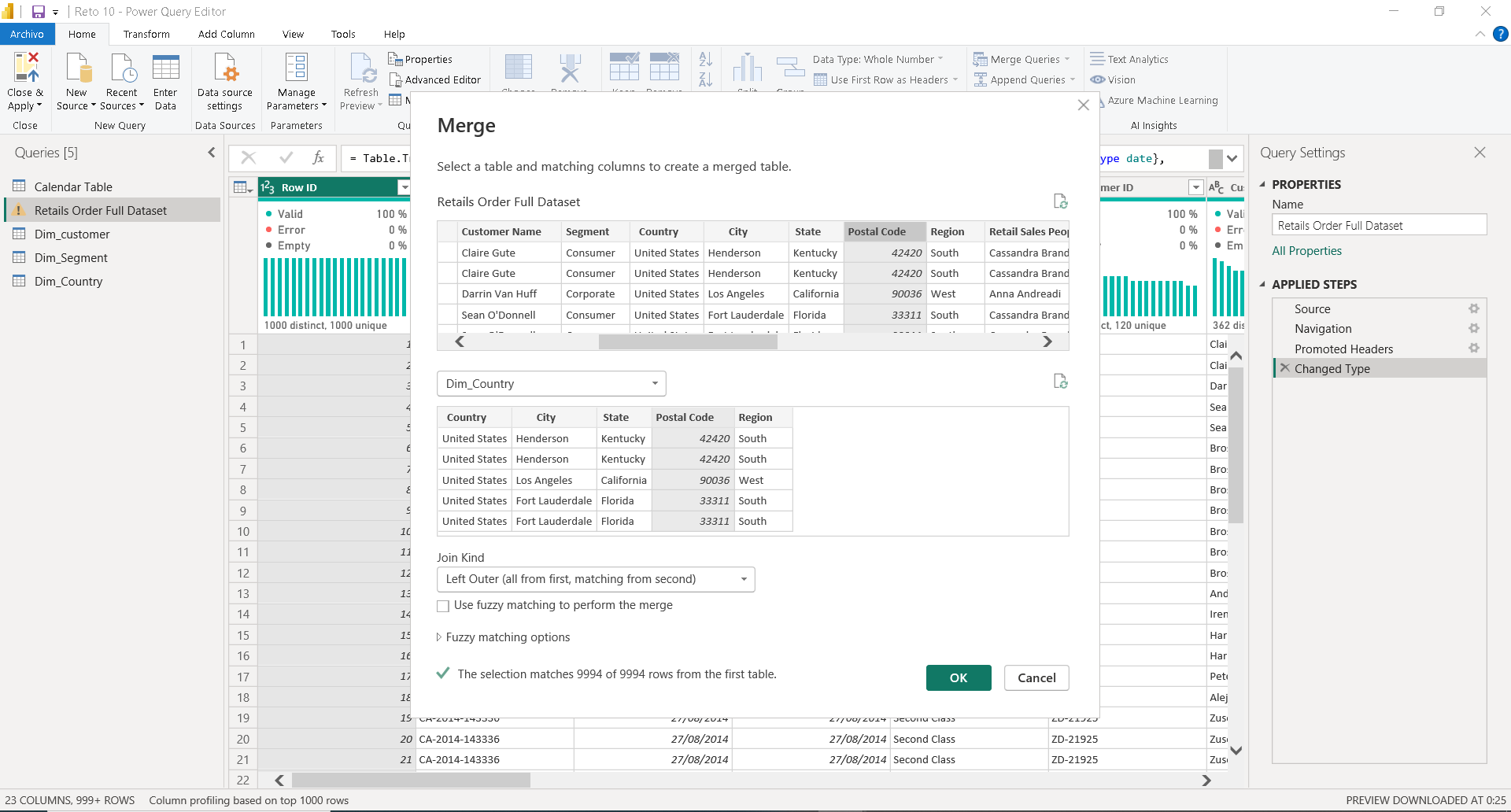 . Sin embargo, cuando seleccionamos «City», que es otra columna de granularidad fina a media, observamos que se pierden registros, como se muestra en la imagen 18.
. Sin embargo, cuando seleccionamos «City», que es otra columna de granularidad fina a media, observamos que se pierden registros, como se muestra en la imagen 18.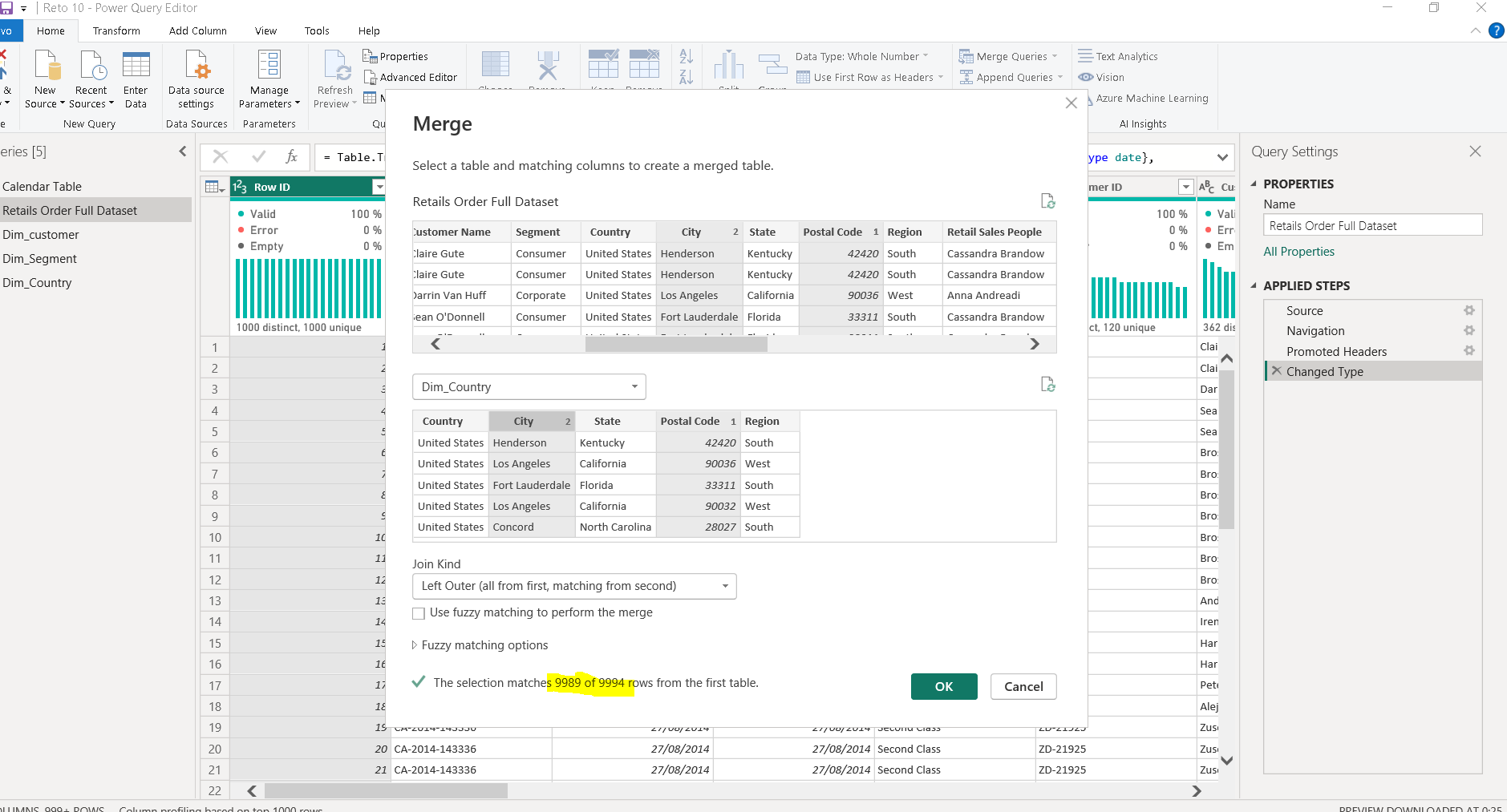
Para determinar exactamente qué datos hemos perdido, ampliamos la columna «Código Postal» del merge y filtramos por valores nulos, es decir, los que no hicieron coincidencia (imagen 19). 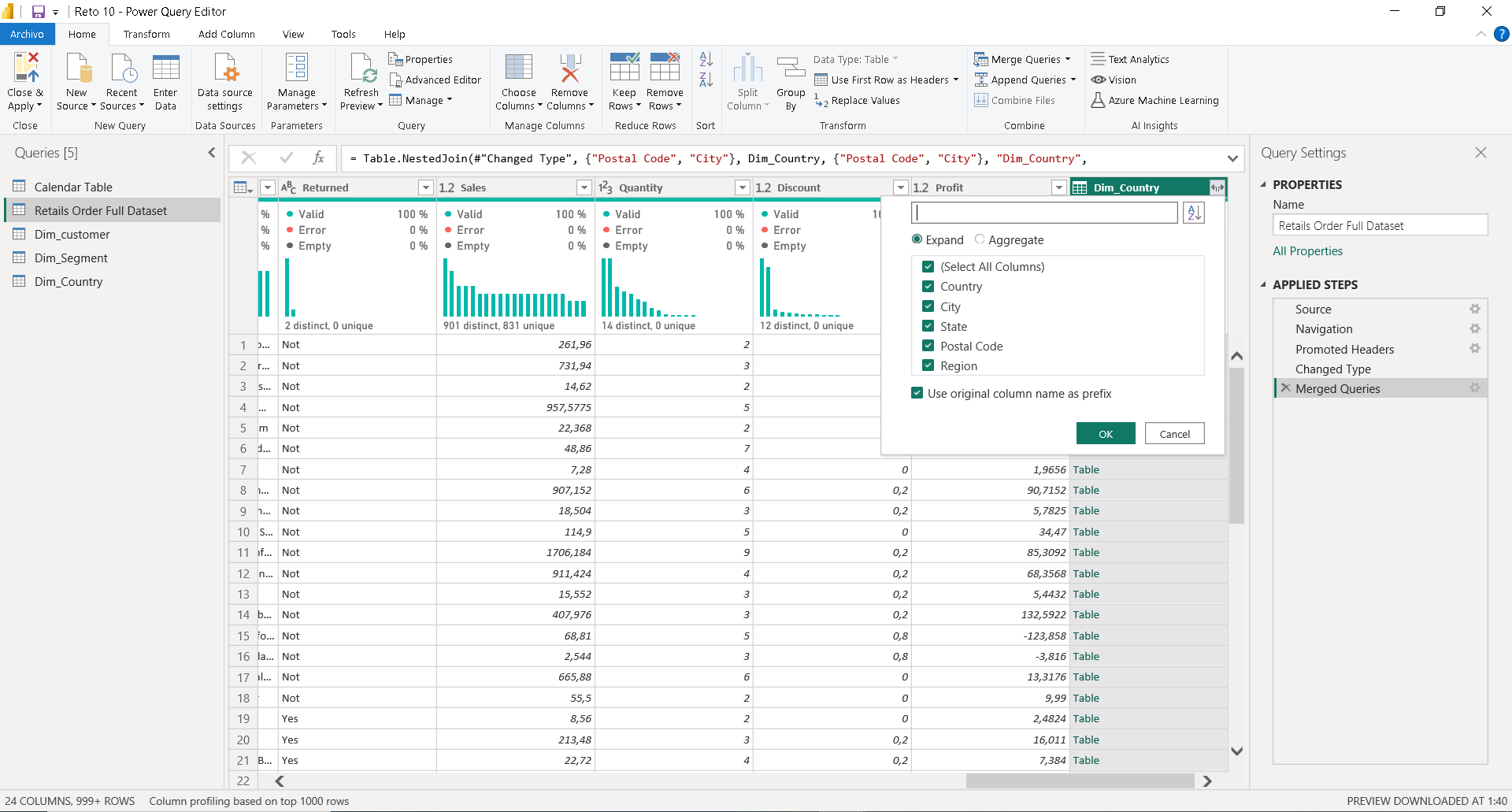 Como resultado, podemos ver que falta la ciudad «Encinitas» con el código postal «92024» .
Como resultado, podemos ver que falta la ciudad «Encinitas» con el código postal «92024» .
Para abordar esto correctamente, tenemos dos opciones. La más sencilla es utilizar la función «Eliminar Duplicados» proporcionada por Power Query, que eliminará eficientemente los duplicados (imagen 20)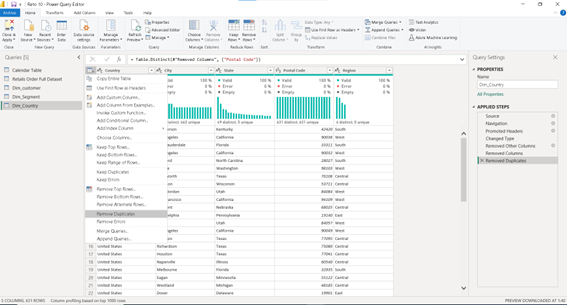 . Sin embargo, si deseamos un control más preciso, podemos eliminar duplicados manualmente seleccionando las dos columnas de menor granularidad (imagen 21).
. Sin embargo, si deseamos un control más preciso, podemos eliminar duplicados manualmente seleccionando las dos columnas de menor granularidad (imagen 21).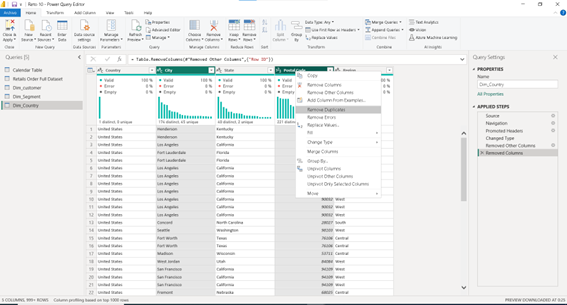
El día de mañana estaré subiendo la segunda fase de la creación del modelo de datos para nuestro reto numero 10.
Business Intelligence Technical.


Perfil linkedin
![]()


Excelente Vicente, muy detallado
Estimado muchas gracias por tus palabras 👍 vamos con toda la energiaaaa!!!