Hoy en este post, vamos a estar Analizando reseñas con NLTK y Python para el reto Pomerol marzo 2023.
El procesamiento de lenguaje natural es una técnica poderosa que se utiliza para analizar grandes cantidades de texto, como en este ejemplo que usamos el fichero para el reto de marzo de pomerol el cual dejo el link acá por si desean participar(https://pomerolpartners.com/dataset_challenge/march-2023/). En Python, una de las bibliotecas más utilizadas(Bueno yo la utilizo muchismo) para procesamiento de lenguaje natural es nltk. Esta biblioteca incluye una variedad de herramientas para el análisis de texto, incluyendo el análisis de sentimientos. En este código, utilizamos nltk para analizar los sentimientos de las reseñas de un archivo CSV y agregar una columna que indica si la reseña es positiva o negativa.
Antes que empecemos con el paso a paso , que es nltk bueno es (Natural Language Toolkit) es una biblioteca de Python diseñada para trabajar con el procesamiento de lenguaje natural. La biblioteca es ampliamente utilizada en la comunidad de procesamiento de lenguaje natural y proporciona una amplia variedad de herramientas para procesar texto en lenguaje natural, como tokenización, análisis sintáctico, análisis semántico y análisis de sentimientos, es decir y en pocas palabras sin tanto tecnicismo que un modulo que nos permite asignarle una cantidad de puntos a las palabras sean negativas o positivas , y sumado a ello se le puede sumar un listado y el peso que contendrán
Importar las bibliotecas necesarias
La primera línea del código importa las bibliotecas necesarias para el análisis de sentimientos. En este caso, utilizamos la biblioteca pandas para leer y escribir datos en un archivo CSV que este será el descargado del reto pomerol, y nltk para realizar el análisis de sentimientos.
import pandas as pd
import nltk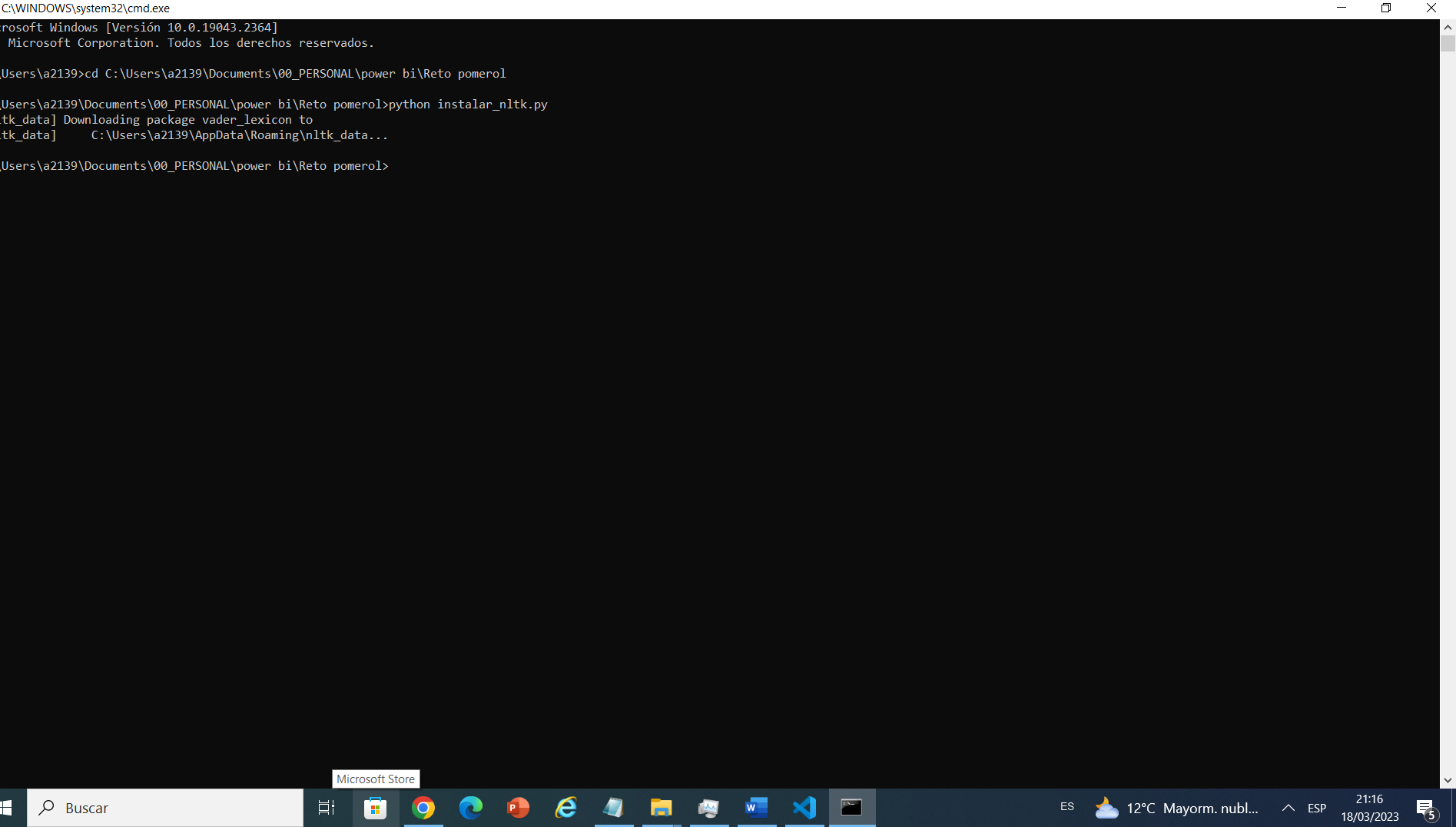
Descargar el léxico para el análisis de sentimientos
La siguiente línea descarga el léxico necesario para realizar el análisis de sentimientos con la biblioteca nltk. En este caso, descargamos el léxico «VADER» (Valence Aware Dictionary and sEntiment Reasoner), que es un enfoque basado en reglas para el análisis de sentimientos, este esta mas sencillo , VADER es las reglas de puntos segun las palabras.
nltk.download('vader_lexicon')Importar el analizador de sentimientos y definir la lista de palabras negativas
En las siguientes líneas, importamos el analizador de sentimientos de la biblioteca nltk y definimos una lista de palabras negativas. Estas palabras serán utilizadas para ajustar los resultados del análisis de sentimientos y dar más peso a las reseñas negativas que contienen estas palabras, esta parte es genial por que seguro te encontraras casos como me ha sucedido que no le da el peso adecuado a ciertas palabras en este caso con este ejemplo fueron estas:
from nltk.sentiment import SentimentIntensityAnalyzer
palabras_negativas = ["don't", 'no', 'Not','Dont','not','never', 'nobody', 'none', 'neither', 'nowhere', 'hardly', 'barely', 'scarcely', 'rarely', 'seldom', 'few', 'little', 'least','problem','Faulty','Never','Not','Defective','defective','fault','affected','wasted']
Actualizar el léxico con la lista de palabras negativas
La siguiente línea actualiza el léxico del analizador de sentimientos de la biblioteca nltk con la lista de palabras negativas definida anteriormente. Esto hará que las reseñas que contengan estas palabras tengan un sentimiento más negativo, luego de identificarlas lo que hacemos es actualizar lo que utiliza en base a nuestra lista y le den los puntos.
analisador_sentimientos = SentimentIntensityAnalyzer()
analisador_sentimientos.lexicon.update({palabra: -2 for palabra in palabras_negativas})
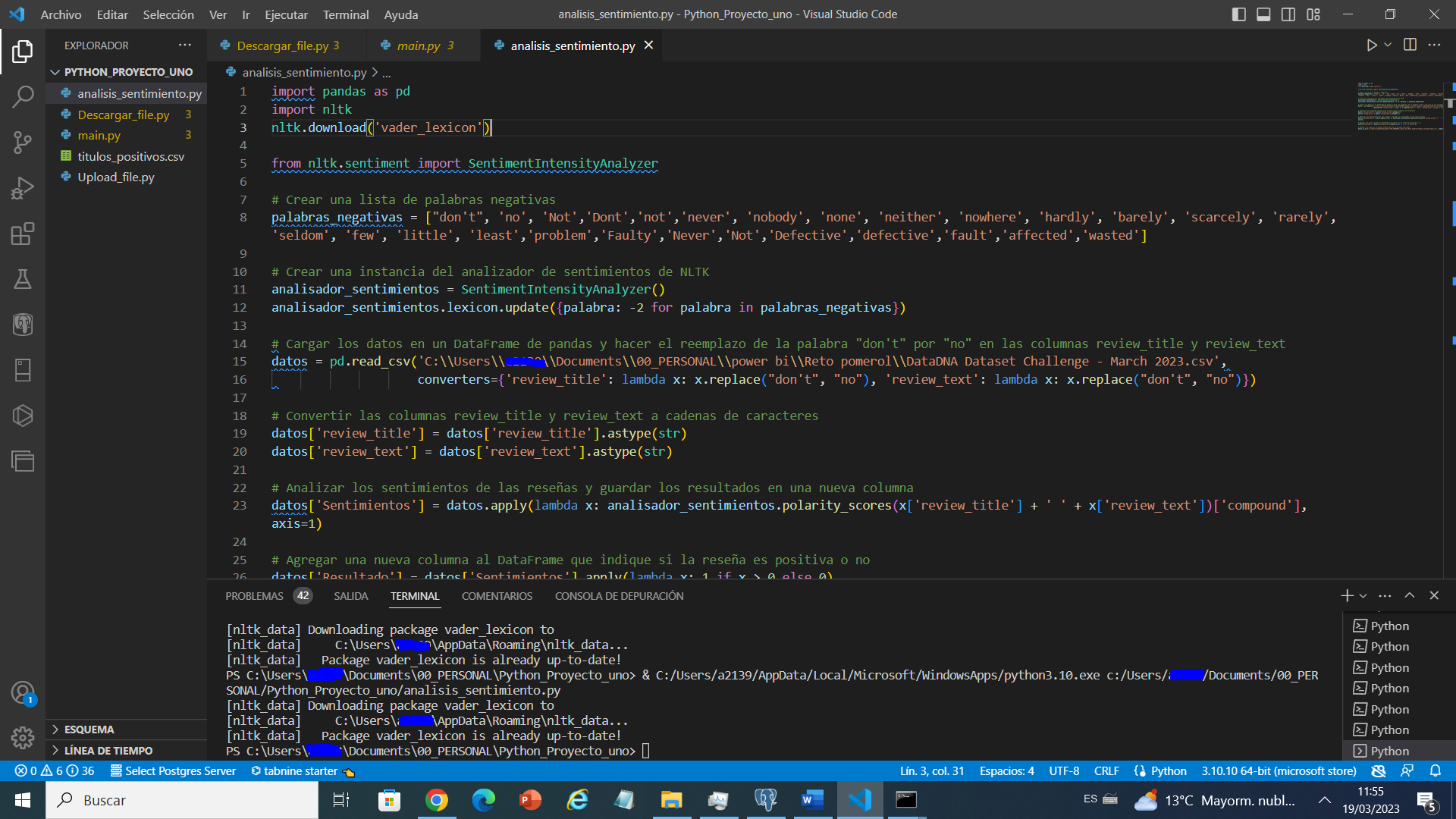
Cargar los datos desde un archivo CSV
En las siguientes líneas, cargamos los datos desde un archivo CSV utilizando la biblioteca pandas. También reemplazamos la palabra «don’t» por «no» en las columnas «review_title» y «review_text» para ajustar el análisis de sentimientos, si te fijas le hago que reemplace en el data set no en el archivo original la palabra «don’t» por no para que identifique y le asigne el peso negativo
datos = pd.read_csv('C:\\Users\\Documents\\00_PERSONAL\\power bi\\Reto pomerol\\DataDNA Dataset Challenge - March 2023.csv', converters={'review_title': lambda x: x.replace("don't", "no"), 'review_text': lambda x: x.replace("don't", "no")})
Convertir las columnas de texto en cadenas de caracteres
En las siguientes líneas, convertimos las columnas «review_title» y «review_text» del DataFrame en cadenas de caracteres utilizando el método astype.
Acá en este caso claro esta debemos entender que en esta columna había también numero así que la transformo a texto antes de que analice a ambas.
datos['review_title'] = datos['review_title'].astype(str)
datos['review_text'] = datos['review_text'].astype(str)Analizar los sentimientos de las reseñas y agregar una nueva columna al DataFrame
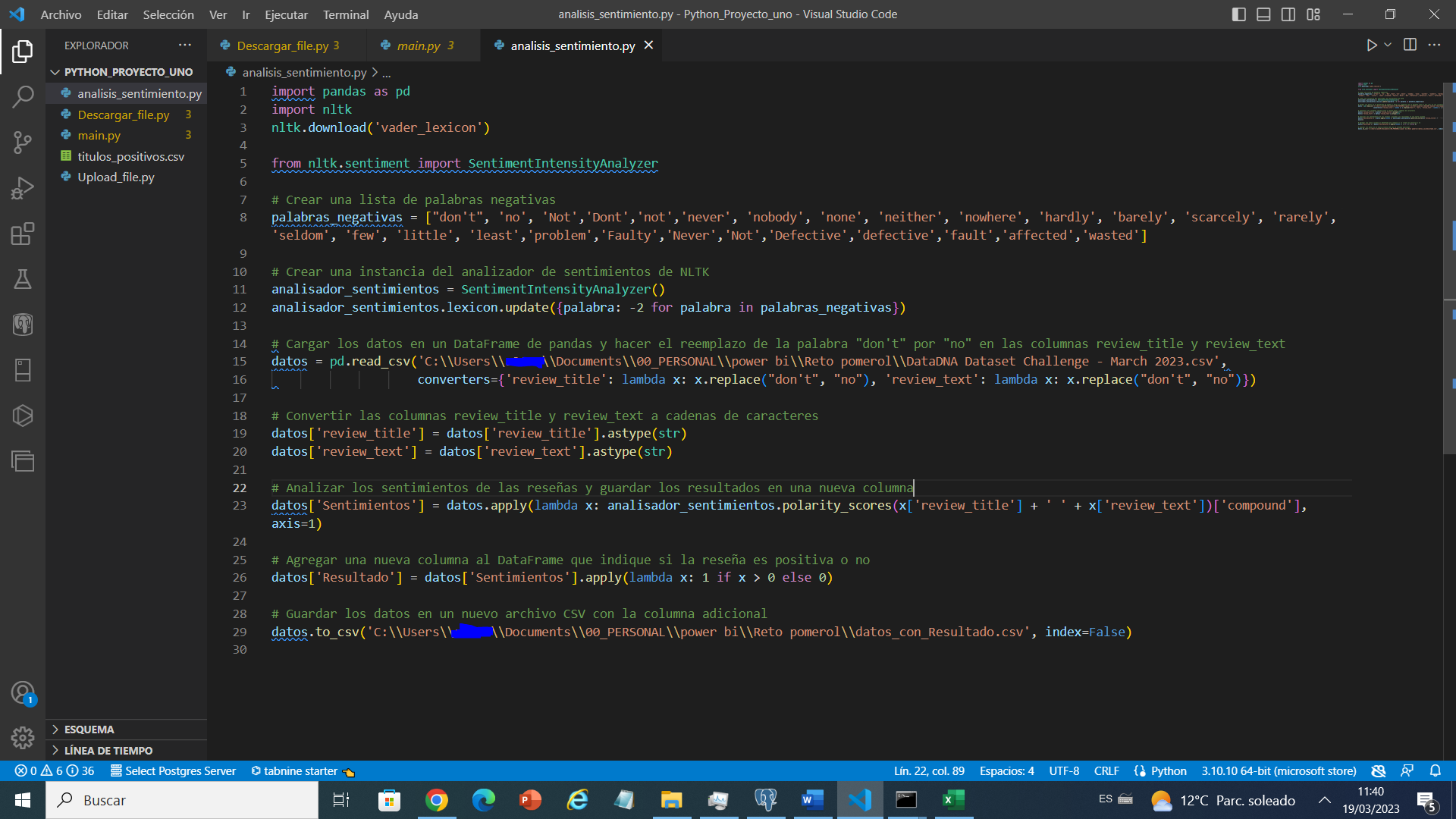
En las siguientes líneas, utilizamos el analizador de sentimientos de la biblioteca nltk para analizar los sentimientos de las reseñas en el DataFrame y guardar los resultados en una nueva columna llamada «Sentimientos». También agregamos una nueva columna llamada «Resultado» que indica si la reseña es positiva o negativa, basada en el puntaje de sentimiento.
Bueno para hacer los más fácil que sele asigna un puntaje en la columna sentimiento y ene el resultado le colocamos 1 positivo y 0 si es negativo.
datos['Sentimientos'] = datos.apply(lambda x: analisador_sentimientos.polarity_scores(x['review_title'] + ' ' + x['review_text'])['compound'], axis=1)
datos['Resultado'] = datos['Sentimientos'].apply(lambda x: 1 if x > 0 else 0)
Guardar los datos en un nuevo archivo CSV
Por último, guardamos los datos en un nuevo archivo CSV con la columna adicional utilizando la biblioteca pandas
datos.to_csv('C:\\Users\\Documents\\00_PERSONAL\\power bi\\Reto pomerol\\datos_con_Resultado.csv, index=false)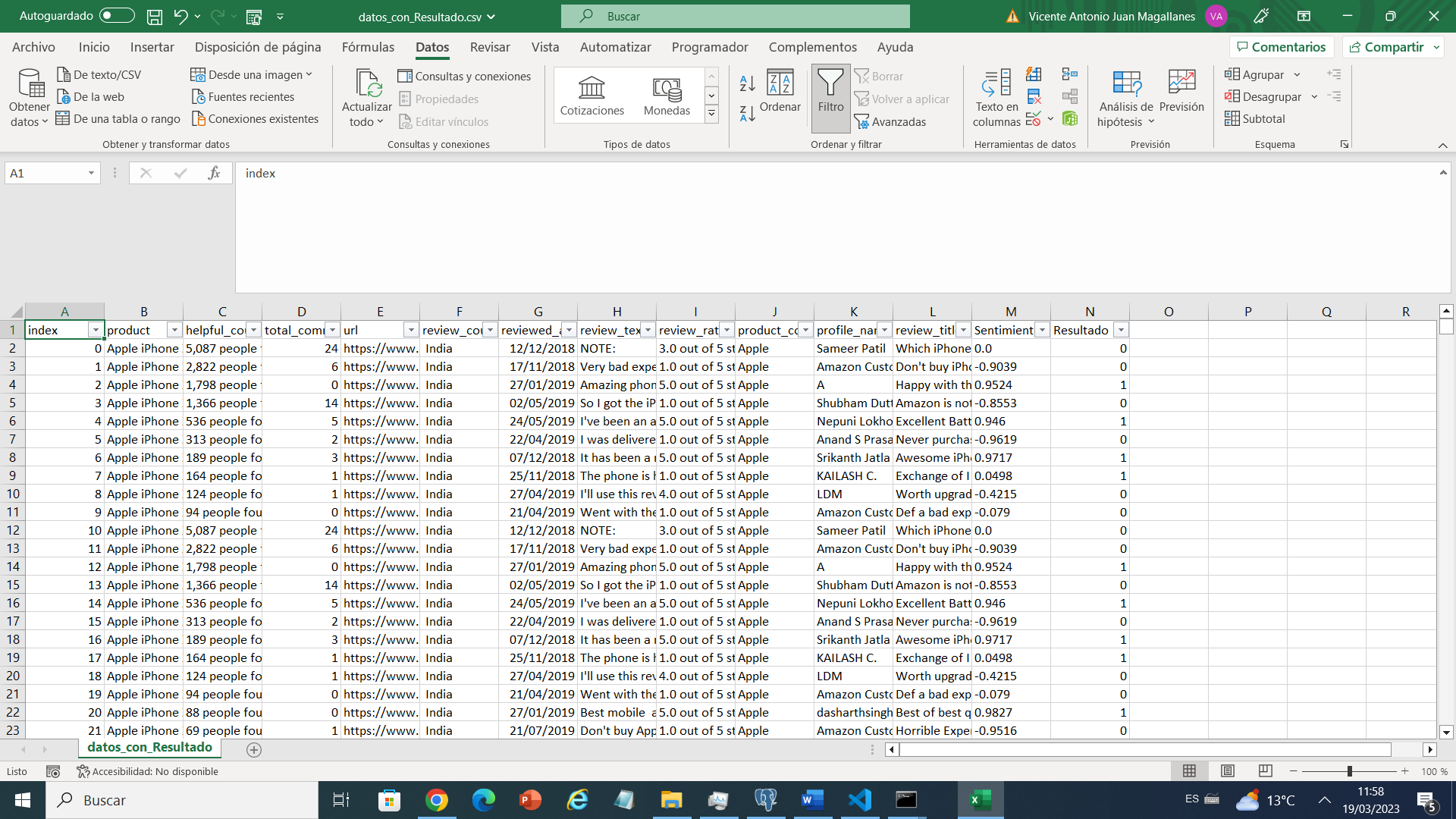
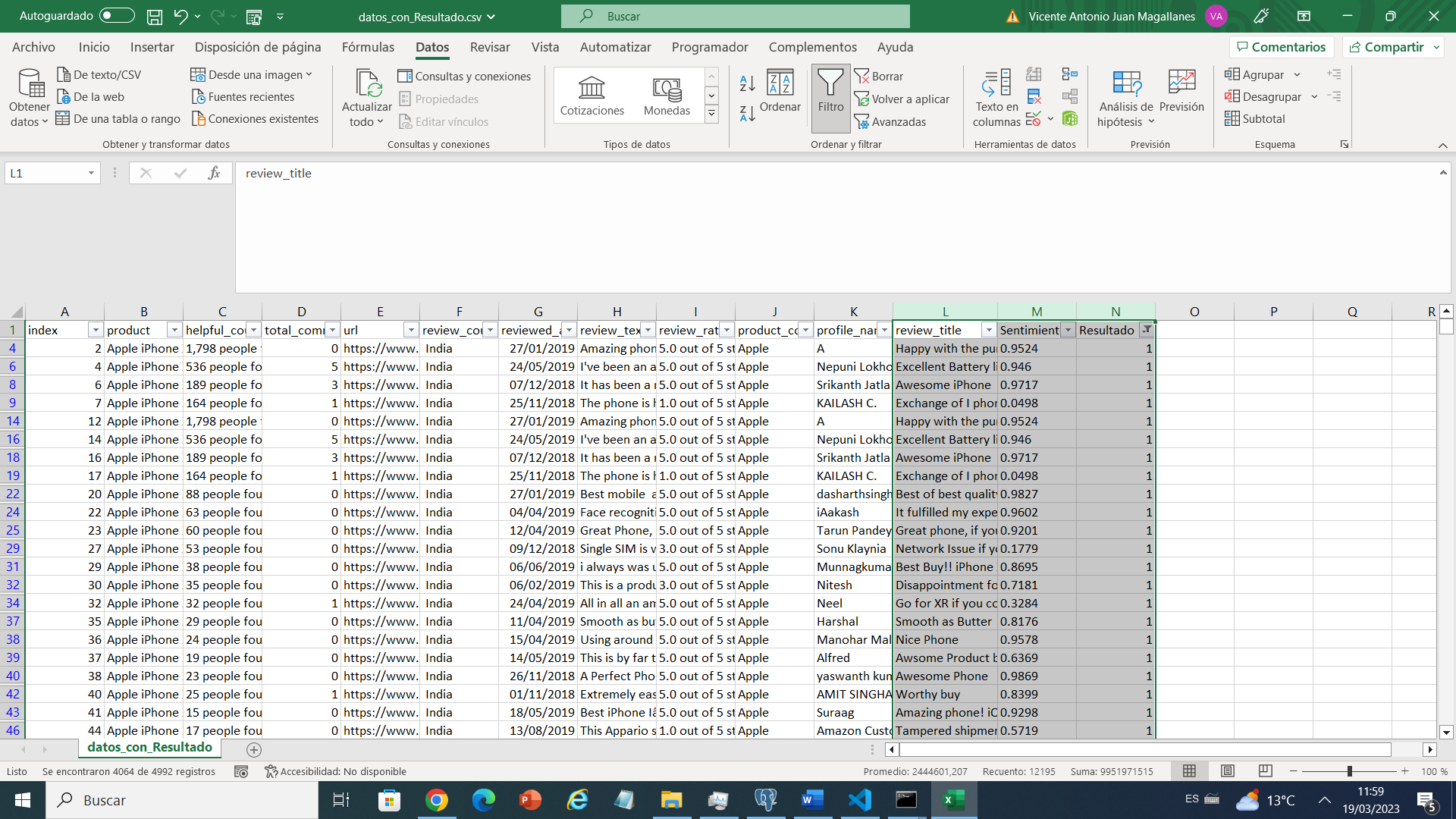
nltk para realizar un análisis de sentimientos en un conjunto de datos de reseñas valora dos columnas y da los puntos para sentimientos y el resultado. A través de la actualización del léxico utilizado por nltk con una lista de palabras negativas y la asignación de puntajes de sentimiento a las reseñas, el código identifica si una reseña es positiva o negativa(Con esto enriquecemos el conjunto de datos) y guarda los resultados en un nuevo archivo CSV. Este código es útil para aquellos que necesitan realizar un análisis de sentimientos básico en un conjunto de datos de reseñas y es una forma efectiva de procesar grandes cantidades de texto para la toma de decisiones.